-

-
-

-
-

-
-

- 010-56548231
-

![]()

![]()

![]()

![]()
![]()
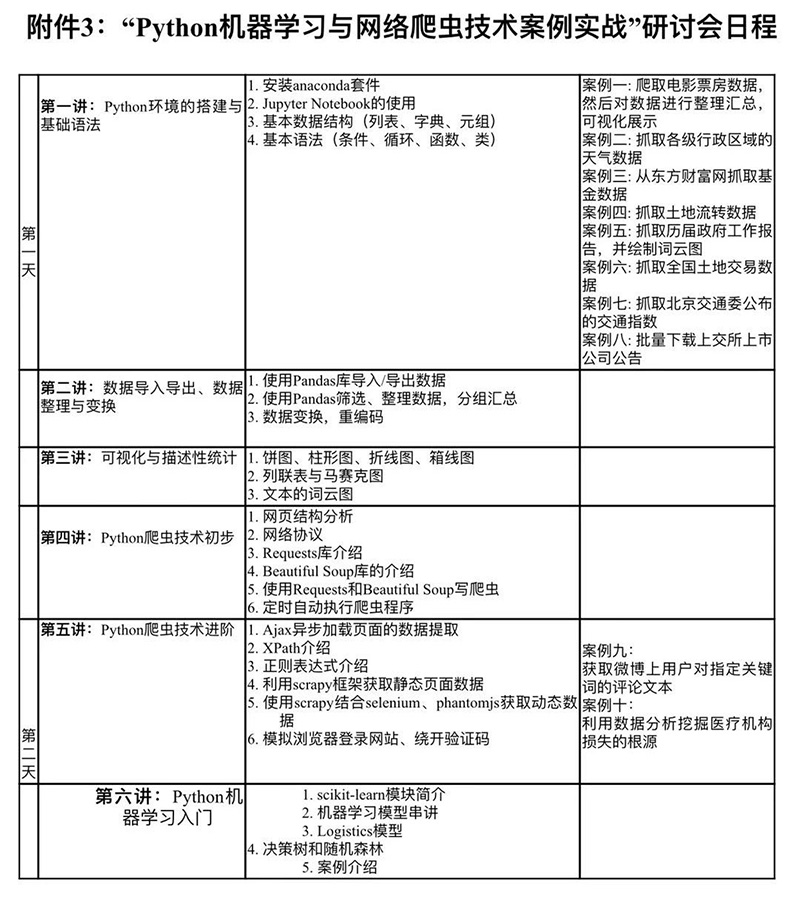
2018年5月5至6日,Python网络爬虫与机器学习案例实战研讨会如期举行。本次培训涵盖爬取电影票房数据,然后对数据进行整理汇总,可视化展示;抓取各级行政区域的天气数据;从东方财富网抓取基金数据;抓取土地流转数据;抓取历届政府工作报告,并绘制词云图;抓取全国土地交易数据;抓取北京交通委公布的交通指数;批量下载上交所上市公司公告;获取微博上用户对指定关键词的评论文本;利用数据分析挖掘医疗机构损失的根源等案例。
2017年,雪晴数据网举办了三期Python爬虫与机器学习应用案例研讨会,取得了非常好的效果。本次Python网络爬虫与机器学习案例实战研讨会,经过我们的反复调研,总结不同场合讲解过课程的内容,经过不断调整打磨,对课程内容和案例进行全新升级更新,挑选出最适合市场趋势的案例和技术来讲解。并辅以案例为主线串联多个知识点,利用遗忘曲线的原理,用多个案例重现数据分析的流程。并根据学员的意愿从案例库里来选择案例讲解,通过简洁的语法编写十几行代码即可实现爬虫功能,并获取海量互联网数据。

本次课程的核心内容包括:Python环境的搭建与基础语法、基本数据结构(列表、字典、元组)、基本语法(条件、循环、函数、类);数据导入导出、数据整理与变换、使用Pandas库导入/导出数据、Pandas筛选、整理数据,分组汇总、数据变换,重编码;可视化与描述性统计,饼图、柱形图、折线图、箱线图、列联表与马赛克图、文本的词云图;Python爬虫技术初步、 网页结构分析、网络协议、requests库介绍、Beautiful Soup库的介绍、使用requests和Beautiful Soup写爬虫、定时自动执行爬虫程序;Python爬虫技术进阶、 Ajax异步加载页面的数据提取、XPath介绍、正则表达式介绍、利用scrapy框架获取静态页面数据、使用scrapy结合selenium、phantomjs获取动态数据、模拟浏览器登录网站、绕开验证码、scikit-learn模块简介、机器学习模型串讲 、Logistics模型、决策树和随机森林等。
参加本次培训的学员分布在市场研究、数据服务、软件开发、电信运营等行业,同时还有一些高校青年教师和研究人员参加。在两天的培训过程中,学员们都积极踊跃的参与到课堂中来。陈老师每讲一小节课都会预留时间给学员自己上机实践。学员遇到问题也可以随时咨询老师和助教,使学员能够及时的消化所学知识。不论您是想要做市场调查、趋势分析、还是想要做科研,都需要从自己机构外部找数据,但是网站有千百种,从单纯的下载文件,到整理成干净的数据表,数据藏在哪里,要拿甚么钥匙去敲门,都是透过每个精心设计的范例去学习的。拿到数据之后,不同的数据类型有不同的处理方式,最后怎么有能力说出一个故事,都是这堂课的学习主轴。

2018年除了Python网络爬虫,我们还会开设R语言爬虫、机器学习、商业数据分析、金融数据分析、计量经济学与R语言、知识图谱、深度学习、人工智能等主题的研讨会。如果您是数据从业人员,数据业务主管,大数据分析与开发的用户,统计学、计算机、数据科学专业的本科以上高年级学生,和从事上述专业的高校教师与实验室人员,那么请加入我们,如果您有培训需求,请列举相关范围,我们尽力满足您的需求。同时我们还提供内训服务,更贴切的现场定制化培训服务,让客户足不出门就可以安心的学习技术了!更多详情请Email至:marketing@uone-tech.cn垂询!热线电话:010-56548231。

2018年第二届Stata中国用户大会大幕开启,这个夏天不见不散,详询:marketing@uone-tech.cn。
