-

-
-

-
-

-
-

- 010-56451129
-

![]()

![]()

![]()

![]()
![]()

Python作为一门面向对象的编程语言,简洁的语法使得编写数十行代码即可实现爬虫功能,获取海量互联网数据。使用Python来编写爬虫实现简单且效率高,同时爬取的数据可以使用Python强大的第三方数据处理库来进行分析,最重要的是学习成本低,如此之好的东西怎能不学习呢?
2017年6月2日至4日,北京理工大学联合雪晴数据网举办了第一期Python爬虫与机器学习应用案例研讨会。本次研讨会取得了非常好的效果,不断有人询问我们何时再次举办类似的研讨会,经过我们的反复调研,对原有的培训内容做全新升级,定于今年7月21日至23日再次举办一期研讨会。
Python爬虫与文本分析应用案例研讨会
主办方:雪晴数据网
雪晴数据网是以数据科学为主题的在线社区,运营实体为绘辰科技(北京)有限公司。网站包含视频课程、问答、资讯等模块。雪晴数据网专注于大数据、数据分析、数据挖掘、数据科学技术的普及和推广,致力于向数据科学从业者提供沟通平台。
雪晴数据网已成为Microsoft高级分析培训团队的在中国大陆地区唯一的合作伙伴,也是RStudio公司在中国大陆唯一的合作伙伴。
● 企业培训介绍
● 线下培训介绍
协办方:北京友万信息科技有限公司,北京理工大学大数据创新学习中心,爬虫俱乐部
合作出版社:清华大学出版社
本课程将主要讲解Python爬虫技术采集数据,并使用文本分析的技术来解决一些市场研究,尤其是产品研究中的一些具体问题,比如产品提及、产品评价、品牌形象等。本课程的授课方式是通过python和knime编程的方式,课程最终目的是实现各种分析的自动化流程,课程成果可以在今后工作中复用。
为什么要学爬虫技术,学了以后有什么好处?
不论您是想要做市场调查、趋势分析、还是想要做科研,都需要从自己机构外部找数据,但是网站有千百种,从单纯的下载文件,到整理成干净的数据表,数据藏在哪里,要拿甚么钥匙去敲门,都是透过每个精心设计的范例去学习的。拿到数据之后,不同的数据类型有不同的处理方式,最后怎么有能力说出一个故事,都是这堂课的学习主轴。
网上有很多爬虫课程,为什么要选我们?
市场上真的有各种爬虫课程,各有各的特色及优点,有的还是免费的,这里我们不比较各自的不同,就说说我们有什么优点吧:
● 优秀的讲师团队:我们的讲师不但有多年的工作经验,也有丰富的教学经验,不但技术过硬,也善于用通俗的语言讲解复杂的知识点,更有耐心为学员解答学习过程中的问题。每次课程我们都会反复研究,花大量时间准备课程材料,力求用最适合的案例和方式为学员讲解。
● 案例教学的方法:我们从2013年开始举办公开的技术培训,也曾多次给企业做内部培训,从多年的教学实践中,我们发现,用传统以知识点讲解为主线,案例为辅的方式,效果并不好。学员反映,听了后面忘前面,学了一堆东西却不知道怎么用。经过多次尝试,我们摒弃了这种教学方式,采用以案例为主线,在案例中讲解知识点的方法,在一个案例中串联多个知识点,利用遗忘曲线的原理,我们用多个案例重现数据分析的流程,学员自然会举一反三了。
● 选取有实用价值的案例:iris数据集、titanic数据、NBA比赛数据跟我们的工作和科研有什么关系?基本没关系,那我们在讲课的时候就不会用这种数据。而且我们教的是如何使用数据分析技术,并不是教你怎么写代码,我们不培养码农的。所以我们选择的案例,都是有现实的商业意义,或者科研价值。在讲解过程中,不但告诉你代码怎么写,还会教你怎么解决问题,为什么要这么做。
● 贴心的助教制度:我们每次开课都会有助教,因为是手把手的课程,助教的存在,就是为了能解答您的问题,确保您有学会,满载回家。而且我们的助教都有实战经验,有的来自业界,有的可能就是前几批的优秀学员,我们也欢迎您以后加入我们的助教或讲师团队。
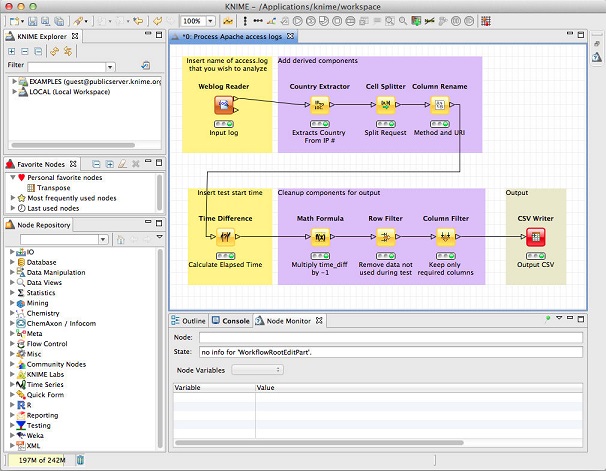
● 对课程品质的坚持:我们在不同场合讲解过课程的内容,不断调整打磨课程,即使是相近的主题,我们也会对课程内容和案例进行升级,挑选出最适合市场趋势的案例和技术来讲解。比如这次Python爬虫与文本分析课程,较6月份的那次课程,我们更换了几乎所有的案例,并在文本分析部分,引入knime软件做为讲解的平台,整个分析过程都在可视化的环境下进行,通过简单的拖曳和设置就可以完成一个分析流程的开发(如下图所示,每个节点都包含一段预先定义好的Python代码,完成分析流程中的一步),这样大大降低了学员的理解难度,提高了Python代码的复用度。
没有学过Python,也可以来上课吗?
当然可以。其实每次都有对编程一无所知的小白来参加我们的课程,他们甚至对电脑的很多知识都不甚了解,经过三四天的课程,不少人不但跟下来了,还很有收获。对python有一点认识的朋友相信一定可以得心应手,针对完全没有碰过python的新手,报名之后我们会推荐您Python的基础在线课程进行课前的练习,也可以提前一天报到,参加我们的课前辅导。
可不可以只学前两天的Python爬虫课程?
当然可以,第三天的文本分析部分比较专业,可能并不适合所有人,你可以只学前两天的课程,也可以只学第三天的课程,费用也不一样,具体的细节请往下看
从事金融、医疗、保险、生态、卫生、计量、统计、银行、通信、环境、基金等与数据分析统计相关的企事业单位技术骨干、科研院所研究人员和大专院校相关专业教学人员及在校研究生、硕士、博士等相关人员,以及广大Python爱好者。
陈堰平,雪晴数据网创始人,北京理工大学大数据创新学习中心导师团成员,2017年1月获“微软最有价值专家”荣誉称号。毕业于中国人民大学统计学院,曾获CQF国际数量金融认证,先后任新华社指数中心技术总监、SupStat Analytics中国区首席技术官。在统计咨询、数据挖掘、开发数据驱动的商业解决方案等领域有近十年的经验,曾为国家统计局、微软、惠普、德勤咨询、联想、丰田、招商银行、花旗银行、东方航空、中国移动、中国电信、中国联通、国家检察官学院等机构做过数据科学方面的培训和咨询。曾开发贝叶斯动态预测模型的R包ssDLM,译作有《R语言编程艺术》、《实用数据分析》和《R语言临床数据分析》,主讲的在线公开课《R语言数据分析入门》、《R语言大规模数据分析实战》已在多个平台上发布,累积学习人数过万人。

曾有杰,人人车计算平台架构师及策略小组负责人,前搜狐大数据平台研发工程师,多年数据分析与开发的工作经验,擅长网络爬虫技术和自然语言处理,对大数据平台、数据挖掘有丰富的实战经验。
谈和,中国传媒大学互联网信息研究院博士生。中国传媒大学大数据挖掘与社会计算实验室研究员,主要负责数据抓取、文本处理以及可视化开发。同时也是中国传媒大学数据新闻专业的授课者之一,负责教授信息图设计制作和可视化编程等技能。目前的研究方向为互联网群体传播与群体行为、社会媒体研究中的自然语言处理。
第一天
案例一: 爬取电影票房数据,然后对数据进行整理汇总,可视化展示
案例二: 抓取各级行政区域的天气数据
案例三: 从东方财富网抓取基金数据
案例四: 抓取土地流转数据
案例五: 抓取历届政府工作报告,并绘制词云图
案例六: 抓取全国土地交易数据
案例七: 抓取北京交通委公布的交通指数
案例八: 批量下载上交所上市公司公告
第一讲
Python环境的搭建与基础语法
1. 安装anaconda套件
2. Jupyter Notebook的使用
3. 基本数据结构(列表、字典、元组)
4. 基本语法(条件、循环、函数、类)
第二讲
数据导入导出、数据整理与变换
1. 使用Pandas库导入/导出数据
2. 使用Pandas筛选、整理数据,分组汇总
3. 数据变换,重编码
第三讲
可视化与描述性统计
1. 饼图、柱形图、折线图、箱线图
2. 列联表与马赛克图
3. 文本的词云图
第四讲
Python爬虫技术初步
1. 网页结构分析
2. 网络协议
3. Beautiful Soup库的介绍
4. 使用Beautiful Soup写爬虫
5. 使用requests和Beautiful Soup写爬虫
6. 定时自动执行爬虫程序
第二天
案例九:获取电商网站的商品评论文本
案例十:获取微博上用户对指定关键词的评论文本
第五讲
Python爬虫技术进阶
1. Ajax异步加载页面的数据提取
2. XPath介绍
3. 正则表达式介绍
4. 利用scrapy框架获取静态页面数据
5. 使用scrapy结合selenium、phantomjs获取动态数据
6. 模拟浏览器登录网站、绕开验证码
第三天
案例十一:根据关键词在社交网络上抓取与汽车、3C产品的相关评论,使用自然语言处理技术做舆情分析、品牌形象评价、意见挖掘和情感分析,用于产品设计和营销决策
第六讲
文本挖掘入门
1. 介绍文本分词的方法
2. 按词性提取关键词
第七讲
产品形象分析和提及率分析
1. 提取与产品或品牌形象相关的描述
2. 了解自己与竞品的提及率
第八讲
用户评价内容分析
1. 构建用户评价指标
2. 提取对应指标中的内容
第九讲
品牌形象和品牌性格分析
1. 品牌形象评价指标的构建
2. 从文本中自动提取出品牌形象各指标值
第十讲
意见挖掘和情感分析
1. 从用户评价中提取用户对事物的评价
2. 分析用户对产品的态度和情感
2017年7月21日-- 23日 北京理工大学(具体地点另行通知)
(时间安排:外地参会人员7月20日报到,21日~23日正式会议,24日安排答疑)
我们推出三种套餐,请根据自身需要选择。以下价格含会议注册费、资料费、场地费。食宿费用自理。
课程套餐
在职人员
学生
第一、二天:爬虫技术
2200元/人
1700元/人
第三天:文本分析
1200元/人
900元/人
全三天课程:爬虫技术+文本分析
3200元/人
2500元/人
参与雪晴数据网奖学金计划,更可以减免大笔学费,只要你足够勤奋,可以免费学!!
针对雪晴数据网注册用户以及北京友万信息科技有限公司的用户,还有一定的优惠,具体优惠幅度请与工作人员咨询。
与会者可申请全国通信和信息技术创新人才培养工程《数据挖掘与分析应用高级工程师》职业技术水平证书,通过考核后即可获得证书,需另交考试费、证书工本费共400元。
1. 为雪晴数据网(www.xueqing.tv)投稿的用户(原创或翻译文章),可以获得代金券(按文章质量,奖励50到200元不等),以抵扣线上线下课程学费,投稿请联系管理员 contact@xueqing.tv
2. 注册并登录雪晴数据网,进入用户中心,然后进入邀请页面(http://www.xueqing.tv/me/invite ),获得邀请链接后,转发给好友,如果对方成功注册,双方都可获得奖励,可抵扣学费。
3.累计五天(可不连续)转发本课程通知到自己朋友圈,并附上推荐理由,截图发给我们的工作人员,报名可优惠200元。
1. 现场班老学员8折优惠
2. 三人以上同时报名9折优惠
3. 五人以上同时报名8折优惠
请填写表格后于7月14日前,发送“报名回执表+支付截图”至邮箱:peixun@uone-tech.cn或直接发送给联络员,邮件主题为:“友万科技python20170721+姓名+单位”。
方式一: 对公转账
开户名 绘辰科技(北京)有限公司
开户银行 中国工商银行股份公司北京大钟寺东路支行
账号 0200151609100034763
方式二: 支付宝
账号 pay@xueqingtv.com
户名 绘辰科技(北京)有限公司
方式三: 现场缴费
外地学员请于7月20号提前报到,北京学员可于21号早上8点~8点半报到,缴费并领取发票和纸质邀请函,以及上课教材。
由于21号早上现场人比较多,鼓励北京学员也于20号报到。
问:是否能开正规发票?
—— 答:我们是正规公司,可以开具增值税普通发票和增值税专用发票,用户根据需要来选择发票类型。
问:我是高校老师,是否可以到现场刷公务卡?
—— 答:可以,我们有POS机,可以打印小票。
问:我是小白,完全不会编程,可以报名参加吗?
—— 答:你可以先看看我们网站的视频课程入个门,再决定是否报名,另外,希望你有大学数学的基础,否则会很吃力。
问:是否提供纸质版会议邀请函?
—— 答:提供,请与我们的工作人员联系。
联系人:陈洁老师
手机/微信:136-6072-3699
QQ :529698127 验证信息请填写友万科技Python培训
Email:peixun@uone-tech.cn
相关新闻链接:
第一届Python爬虫技术与机器学习实战研讨会圆满落幕
全新升级!!Python实战案例研讨会:爬虫与文本分析(雪晴数据网)
Python爬虫与文本分析应用案例研讨会报名回执表下载
 北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
地址:北京市昌平区中兴路21号院4号楼5层516 网站备案号:京ICP备16049373号-1]
联系方式:+86-10-56548231
