-

-
-

-
-

-
-

- 010-56548231
-

![]()

![]()

![]()

![]()
![]()

Veda 在梵语中意为“知识”。它是将建模者的知识转化为模型的输入,并将模型的输出转化为知识的软件工具。Veda2.0 是集成 MARKAL-EFOM 系统 (TIMES) 的数据处理系统 - 能源环境系统的自下而上优化模型。它使用 C#.NET 作为 UI 和 PostgreSQL 作为后端。Veda 基于模块化方法,将模型输入数据和结果组织到一个集成数据库中。通过表格浏览(数据立方体)和网络图可以看到信息。它用于开发和管理模型运行以及分析模型结果。
● 能源建模人员使用的大部分数据都已经在电子表格中,或者可以很容易地到达那里。该界面应该能够读取分析师认为直观的格式,而不是强迫他们通过单独的 UI 输入信息。
● 假设应以原始形式表达;数据预处理应该是最少的。
○ Veda 可以读取各种布局 - 时间序列、列中的区域、列中的属性等,以最大限度地减少结构预处理。
○ Veda 允许基于规则的参数操作和集合声明,以最大限度地减少数值预处理。只需很少的指令即可引入或修改大量数据。
● 系统应该是模块化的——易于激活/停用/替换扇区或区域。不同的分析师应该能够同时在不同的部门或地区工作。
● 跨区域通用的结构和数据应仅声明一次。
● 不同层次的假设应该共存,以便它们可以在运行时被激活/停用/排列。
以下是在过去二十年中 Veda 的特殊含义的一些关键字。
● Templates:模板通常被定义为确定或用作模式、模型的东西。在 VEDA 世界中,这是指构成模型的所有 Excel 文件。
● Template Folder:包含所有这些文件的文件夹称为模型的模板文件夹。
● Scenario:最接近的正常定义是想象的或预计的事件序列,尤其是几个详细的计划或可能性中的任何一个。这可能是 MARKAL/TIMES 建模者一直使用的最棘手的误称。它用于模型输入和输出的不同含义。在输入端,这意味着一堆可以命名的输入数据。示例:所有起始年份数据通常称为 BASE 场景;CO2 Tax 的时间序列可以称为 CO2Tax 场景;对水电和风电未来容量限制的假设可以称为 RenewablePotential Scenario。我们选择一组这样的场景,并在提交运行时给它一个案例或运行名称。当处理具有此案例/运行名称的解决方案时,它又被称为场景。通常,此名称代表证明运行合理的关键假设——例如 CO2_tax_100、Hi_RE_potential。
● Transformation:正常定义是根据数学规则将表达式更改为另一个表达式的操作。在这里,它用作用于以基于规则的方式创建新数据(或修改现有数据)的表的形容词。
● SubRES:这通常没有意义;这是我们对英语的原创贡献!按照 RES 的常规含义 - 参考能源系统,这是指模型整体 RES 的一部分。通常,这是一组可以在不中断核心流程的情况下从模型中包含/排除的流程和商品。封存将是一个很好的例子:为封存建模而创建的所有流程和辅助商品都可以放在一个独立的 SubRES 中,这样它们就可以自由地包含/排除在模型运行中(在提交运行时),而无需更改任何参数值。这些通常用于定义模型的新技术。
● Base-Year:建模范围的第一个时期。由于 TIMES 允许灵活的周期长度,通常这是一年,因此这些值是年度值而不是几年的平均值。
● Super-Region:它是一个用户定义的标签,映射到一个或多个模型区域。该映射在 SysSettings 文件中声明。例如,请参见 DemoS_005 模型中此文件的工作表“Region-Time Slices”;“REG”映射到 REG1 和 REG2。Demo_Adv_Veda 模型对此功能的使用更为丰富。
● Dummy Imports:为避免因 RES 连接断开或校准范围太紧而导致的不可行性,VEDA 为模型中定义的每个 NRG、MAT 和 DEM 商品创建了一个虚拟源。基本思想是让这些来源的供应价格比模型中的正常价格高出一个数量级,这样就可以很容易地找到潜在不可行性的来源。为每种商品类型创建一个流程,并且可以通过 SysSettings 文件(或任何其他场景文件)来控制它们的操作成本。
● SYNC:同步,用于从 VEDA 导航器启动的操作,它将各种 Excel 文件的信息读入数据库。
所有输入数据都驻留在 Excel 工作簿中。Veda2.0 推荐 XLSX/M 格式。模块化是 Veda 的核心特征之一。这是为了使主要的重新配置成为可能和高效。这也使得多人更容易并行处理模型的不同部分。这是通过将输入数据分成以下部分来实现的:
● 区域、时间片、建模年份和商品的核心定义
● 现有库存的技术
● 新技术
● 需要
● 行业
● 技术和商品的附加参数定义
除了第一个 - 核心定义之外,每种类型的数据可以有多个文件。在每个模型文件夹中,这些文件的组织结构如下所示。
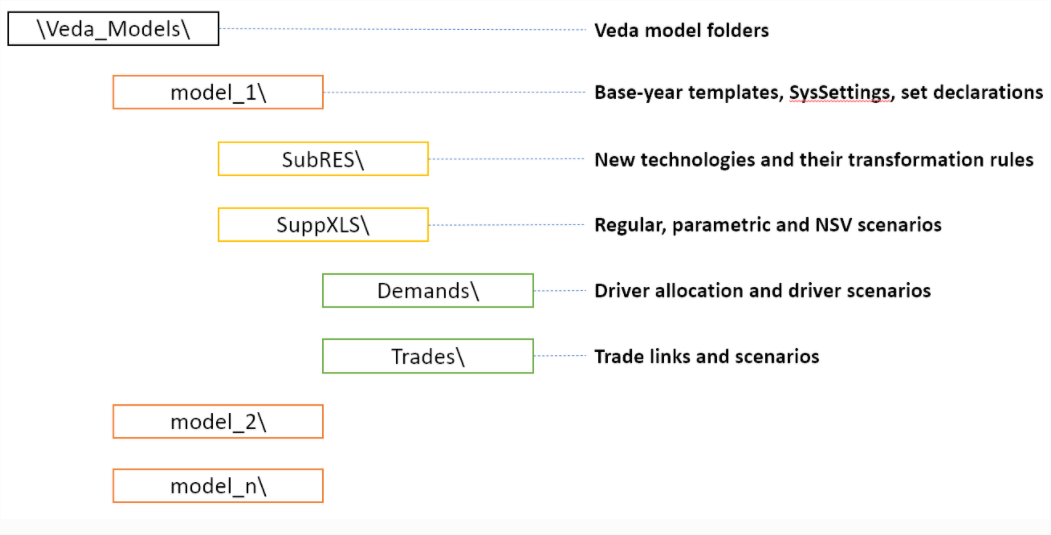
这些子文件夹中预期的文件如下:
● 根文件夹有 SysSettings(核心定义)、Base-year 模板(现有技术)和设置定义。
● SubRES 有新技术的文件
● SuppXLS 有场景文件(所有现有和新技术和商品的附加参数(或修改))
○ Demands 有 DEM_Alloc+Series 来为需求分配驱动程序,ScenDem_
○ Trades 具有用于定义贸易链接的 ScenTrade__Trade_Links 和用于声明贸易流程属性的 ScenTrade_<场景名称>(也可以在常规场景文件中完成)。
Veda2.0 是一个 C#.NET 应用程序,它将这些 Excel 文件读入 PostgreSQL 数据库,提供数据的表格和图形视图作为 TIMES 参数,并将数据提交给 TIMES 代码。
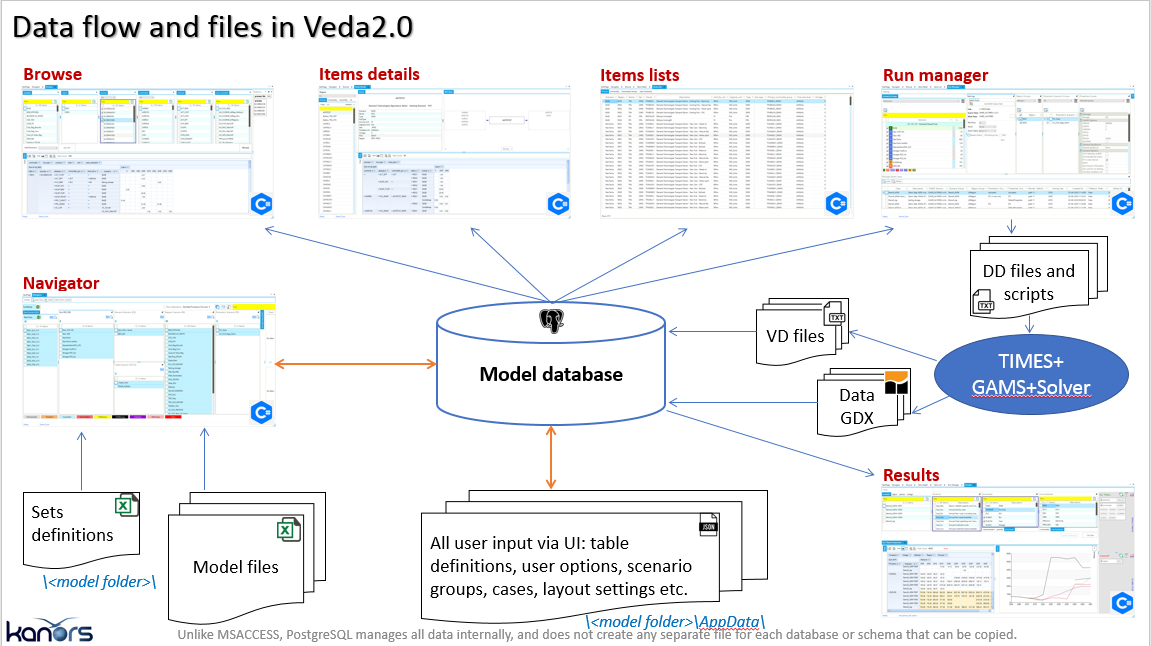
Veda2.0 共有三个不同的版本:
● Academic
● Standard
● Advanced
Academic版本在单核上运行,但仍然比 VEDA_FE/BE 快得多。Standard版本使用多核进行某些操作,如处理 FI_T 和 DINS 标签,以及写入 DD 文件。在较小的模型(学术用途)中,差异是难以察觉的。高级版有两个附加功能 - 协作和报告。
在服务器上处理同一模型的多个用户将能够共享以下内容:
● 模型运行
○ 来自多个用户的运行,即使具有相同的名称,也可以在结果模块中使用。“用户”将是数据中的一个维度,如地域、场景等。
● 输入数据 GDX
● 结果视图定义
● Run Manager 的各种组和案例定义
此外,Appdata 文件夹中的 JSON 文件也会保留用户名信息。因此,共享模型文件夹的用户将能够使用或过滤掉其他用户创建的组、案例和视图。
Veda2.0 中的 VEDA_BE 和结果功能非常适合交互式和生产报告。但是有两个限制,删除它可以使它更强大和灵活。一、报告变量被困在表格中——我们无法直接控制它们。其次,我们不能为输出视图添加维度——在对输出进行分割时,我们仅限于流程和商品集,超出了属性、区域和时间等原生索引。让我们以运输最终能源(在像 JRC_EU-TIMES 这样的丰富模型中)为例:我想按场景、区域、燃料、模式、规模和技术查看能源消耗。场景和区域是单独的指标,燃料可以用商品集来管理。但我们只有流程集来处理模式、规模和技术。自定义报告的全新方法使用 Excel 模板以非常有效的方式定义报告变量,并自由添加基于过程/商品名称、区域和场景的维度。更远,可以在此过程中包括外生数据。它可用于包括历史能量平衡以在摘要视图中显示历史趋势,并设置校准检查视图。
许可证也像以前一样根据机构定价。学术版仅供授予学位的机构使用。

● 各种浏览功能、运行管理器,甚至导航器,都非常独立地工作,可以同时使用。可以同时使用多个模型。
● 新的起始页使使用模型以及 Git 上的不同分支变得容易。有一个部分从互联网上提取信息——用于向用户显示提示。
● 所有枢轴网格都有 CSV 导出工具,这对于为 Power BI 和 Tableau 等可视化工具创建输入非常有用。
● 单位转换更高级。
● 可以在 RUN 文件的不同位置和 DD 文件的顶部或底部编写 GAMS 指令。
● 可以直接指定里程碑年,而不是使用期间长度。
● 所有表格都非常独立,允许非常灵活的布局更改。即使正在写入 DD 文件或正在同步模型,用户也可以继续使用其他模块。
● 同步速度快三到十倍,具体取决于模型结构和可用内核数量。
● 为进一步减少处理时间提供了指导。
● DD 写入速度快了一个数量级,并且直接随着内核数量的增加而扩展。
● 整个应用程序都可以使用智能过滤。
● 与以前一样,所有数据都呈现在枢轴网格中以供浏览,但枢轴工具得到了很大改进。
● 方便的图表工具可用于所有数据视图。
● 跟踪和报告场景文件之间的相互依赖性(由于 FILL/UPD/MIG 表)。
● 任何标签的列位置,包括 FI_T 和 UC_T,都不再重要,因此不容易出错。
● 每个支持的所有标签和列的综合文档。
● 集合定义由输入和结果部分共享,过去很难保持同步。现在,sets 文件由两个函数无缝同步。
● 强大的集游乐场功能允许交互式查看、编辑和创建新集,这些新集会在集定义文件中自动更新。
● 开放架构:所有用户定义,如场景组、案例、结果视图等都存储在(待记录)json 和 CSV 文件中。原则上,用户可以通过编程方式修改这些文件。
Veda2.0 适用于装有 Windows 8/Windows Server 2012 或更高版本的 Windows 便携式电脑、台式机、服务器和虚拟机。Microsoft Excel 是先决条件。所需的硬件取决于模型的大小和复杂性,但这里是适用于 Veda2.0 下典型 TIMES 模型的配置:
CPU:建议 STANDARD 和 ADVANCED 许可证至少使用 4 核。8 - 16 对于较大的模型是可取的
RAM:4-8 GB 对 Veda 来说足够了,但 GAMS 需要更大的 RAM 来处理更大的模型。32 GB 可容纳大多数型号
HDD:500GB - 1TB 可用空间用于 Veda 和 GAMS 文件
 北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
北京友万信息科技有限公司,英文全称:Beijing Uone Info&Tech Co.,Ltd ( Uone-Tech )是中国大陆领先的教育和科学软件分销商,已在中国300多所高校建立了可靠的分销渠道。拥有最成功的教学资源和数据管理专家。如需申请软件采购及老版本更新升级请联系我们,咨询热线:010-56548231 ,咨询邮箱:info@uone-tech.cn 感谢您的支持与关注。
地址:北京市昌平区中兴路21号院4号楼5层516 网站备案号:京ICP备16049373号-1]
联系方式:+86-10-56548231
