-

-
-

-
-

-
-

- 010-56451129
-

![]()

![]()

![]()

![]()
![]()
 Stata 17—数据统计分析软件包
Stata 17—数据统计分析软件包


2021年4月20日 Stata 17 全新版本正式上线!它有许多令人兴奋的新功能,包含29个亮点!
Stata 是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。它功能非常强大,包含线性混合模型、均衡重复反复及多项式普罗比模式。用Stata绘制的统计图形相当精美。Stata具有操作灵活、简单、易学易用、运行速度极快等优点。 <<点击了解详情。
2021年 "论文实证方法与Stata应用专题研讨会" 圆满结束!
重要通知!Stata 16.1发布,所有Stata 16用户可免费更新升级!
热烈祝贺“第三届Stata中国用户大会”在上海财经大学成功举办并取得圆满成功
2019 Stata夏季训练营暨Stata空间计量与机器学习研讨会于上海财经大学成功举办
2019 Stata夏季训练营暨机器学习与Stata、R应用研讨会在上海财经大学成功举办
2020 Stata中文在线研讨会 | Stata自动生成报告工具及演示
第三届Stata中国用户大会暨“Stata机器学习与计量方法应用研讨会”
2021年4月20日,Stata 17全新版本正式发布!!
全新的Stata 17给我们带来了怎样的惊喜呢?总结起来,主要有以下十个方面,下面分别介绍:
1、双重差分法的官方命令
2、完美的表格输出
3、Lasso的新功能
4、离散选择模型的新命令
5、久期数据的新命令
6、贝叶斯计量经济学的全面升级
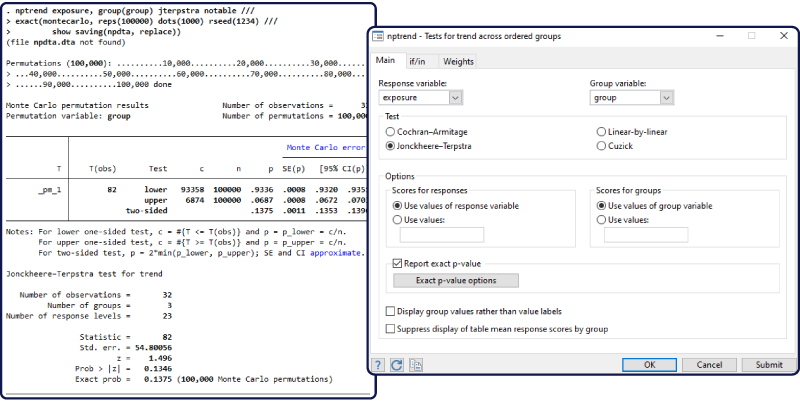
7、非参数的趋势检验
8、元分析的新命令
9、Stata与Python、Java、H2O 及 Jupyter Notebook的整合
10、Do文件编辑器的改进与Stata速度提升等
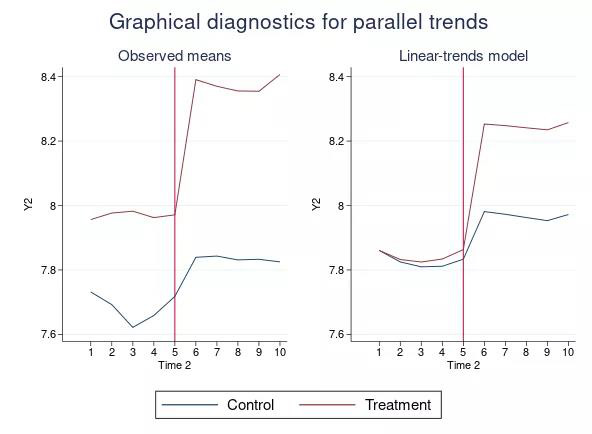
“双重差分法”(Difference-in-differences,简记DID)或许是最常用的计量方法。怎么能没有DID的Stata官方命令呢?为此,Stata 17及时地推出了DID的官方命令xtdidregress;其中,“xt” 表示这是适用于面板数据的命令。 除了进行常规的 DID 估计,命令xtdidregress还允许最多指定三个“分组变量”(group variables),或两个分组变量与一个时间变量,从而进行“三重差分法”(Difference-in-differences-in-differences,简记DDD)的估计。 另外,针对“重复截面数据”(repeated cross-sectional data),即所谓“准面板”(pseudo panel data),Stata 17也推出了相关的新命令didregress,可进行类似 DID 的估计。更重要的是,你可以用DID的官方命令,轻松地画平行趋势图啦~
实证研究者经常需要将Stata的多个回归结果以表格形式输出到Word文件中。虽然早有官方命令estimates table可完成此类任务,但比较死板;故此前Stata用户一般使用非官方命令(比如estout或outreg)来输出回归结果。为此,Stata 17大幅改善了原来的table命令,使用户可轻松地以表格形式汇报回归结果(regression results)或统计特征(summary statistics)。
进一步,你可以设计回归表格的风格(styles),并应用于所创建的表格,然后将此表格输出到Word或其他形式的文件(包括PDF、HTML、LaTex、Excel、Markdown 等)。另外,你还可以使用新增的前缀(prefix)collect,来收集Stata命令的各种估计结果。最后,Stata 17还新增了Table Builder(表格创建器),让用户可通过点击鼠标(point-and-click)来创建表格。

作为“高维回归”(high-dimensional regression)的常用工具,Stata 16已经推出了有关Lasso(Least Absolute Shrinkage and Selection Operator,即所谓 “套索估计量”)的一系列官方命令。Stata 17则提供了更多有关 Lasso 的新功能。
使用Lasso估计处理效应模型。在 Stata 16 中,可使用命令teffects估计“处理效应”(treatment effects)模型;而命令lasso则用于估计协变量很多的高维模型。Stata 17则将二者结合起来,其推出的新命令telasso,可估计包含很多协变量的处理效应模型。

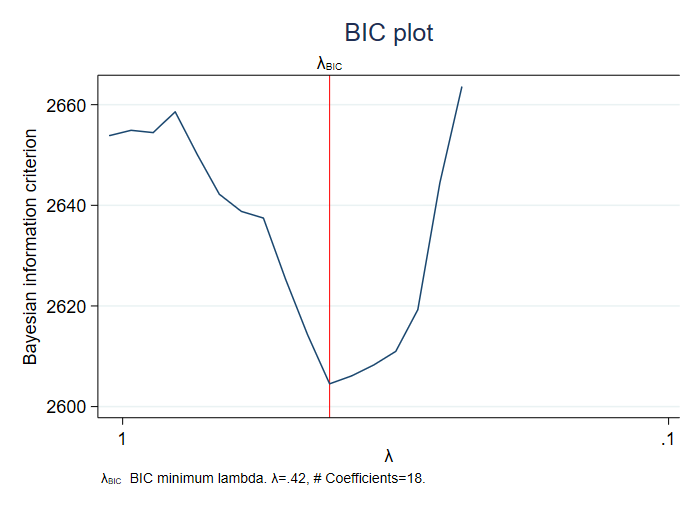
使用 BIC 选择Lasso惩罚参数。作为一种“惩罚回归”(penalized regression),在进行Lasso估计时,需要选择惩罚参数(penalty parameter)。在Stata 16中,可使用交叉验证(cross-validation)、适应性方法(adaptive method)或代入法(plugin)来选择惩罚参数。
在Stata 17中,新增了选择项 “selection(bic)”,可使用 “贝叶斯信息准则”(Bayesian Information Criterion,简记BIC)选择惩罚参数。而且,新增的估计后命令(postestimation command)bicplot 可以很方便地将此选择过程可视化。
使用Lasso处理聚类数据。对于“聚类数据”(cluster data),由于每个聚类中观测值存在自相关,故通常的Lasso估计可能导致偏差。在Stata 17中,在使用命令lasso或elasticnet时,可通过新增选择项 “cluster(clustvar)” 来处理聚类数据。进一步,对于使用Lasso进行统计推断的命令,比如poregress(表示partialing-out regress),则可使用Stata 17的新增选择项 “cluster(clustvar)” 来得到聚类稳健的标准误(cluster-robust standard errors)。
离散选择模型(discrete choice model)是微观计量经济学的常用模型。在Stata 17中,增加了以下离散选择模型的新命令:
“面板多项逻辑模型”(panel multinomial logit model)。对于横截面数据的多项逻辑模型,Stata已有mlogit命令。Stata 17新增的xtmlogit命令则可使用面板数据估计多项逻辑模型。这无疑是Stata在离散选择模型方面的一大进步,因为此前Stata只能使用xtlogit或xtprobit估计面板二值选择模型。
“零膨胀排序逻辑模型”(zero-inflated ordered logit model)。对于排序数据(ordered data),此前可使用Stata命令ologit或oprobit进行估计。在实践中,有时排序数据中最低类别所占比重很大。若将最低类别的取值记为“零”,则存在所谓“零膨胀”现象。此时可使用Stata 17的新增命令ziologit,估计更有效率的“零膨胀排序逻辑模型”(zero-inflated ordered logit model)。

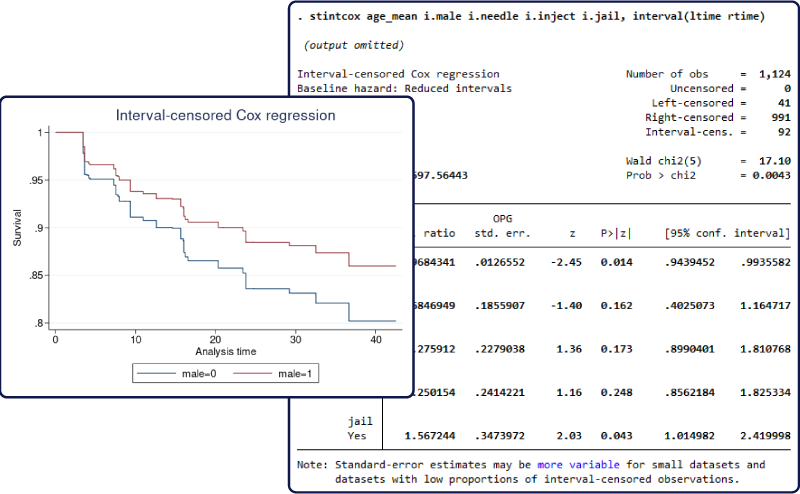
“久期数据”(duration data)常用于生物统计的 “生存分析”(survival analysis),在经济学中也有广泛用途,例如失业的持续时间,婚姻的延续时长,王朝的寿命等。久期数据常存在 “删失”(censoring)或 “归并” 问题,比如当研究结束时,有些病人可能尚未死亡;或者有些失业者还未找到工作。
Stata 17新推出的命令stintcox,可使用Cox模型来估计一种特殊的“区间删失”(interval-censored)数据。对于区间删失数据,我们只知道事件发生于某个区间,但无法确知其发生时点;比如,只知道癌症复发于两次体检之间的时段。如果忽略久期数据存在的区间删失问题,则会导致估计偏差。
在大数据时代,由于数据日益复杂而多样,在处理有些问题时,基于频率学派的传统计量方法可能不便使用,使得贝叶斯学派的计量经济学逐渐兴起。频率学派认为待估计的参数是给定的未知数(fixed unknown parameters),而贝叶斯学派则将未知参数视为服从某个分布的随机变量,并可随时根据新的样本信息将其 “先验分布”(prior distribution)更新为 “后验分布”(posterior distribution)。
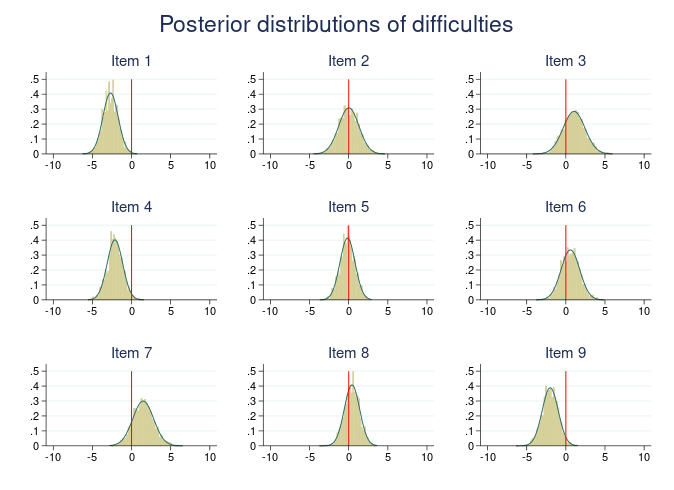
Stata 17将Stata中原有的贝叶斯统计学与计量经济学进行了全面升级。
贝叶斯面板数据模型(Bayesian panel-data models)。Stata目前已有的面板命令包括xtreg(静态面板),xtlogit或xtprobit(面板二值选择模型),以及xtologit或xtoprobit(面板排序模型)等。在 Stata 17中,如果要使用贝叶斯方法估计这些面板模型,只要在原命令之前加上 “前缀”(prefix)bayes即可。

贝叶斯向量自回归模型(Bayesian VAR models)。“向量自回归”(Vector Autoregression,简记VAR)是常见的时间序列模型。在已有的Stata中,可用命令var来估计VAR模型,而后续命令则包括:使用fcast进行 “动态预测”(dynamic forecast),以及使用irf估计 “脉冲响应函数”(impulse response function,简记 IRF)与 “预测误差方差分解”(forecast error variance decomposition,简记 FEVD)。
在Stata 17中,则可使用命令“bayes: var”(即在命令var之前加上前缀 bayes)估计贝叶斯的 VAR 模型,然后用bayesfcast进行动态预测;而脉冲响应函数与预测误差方差分解也可类似地得到。
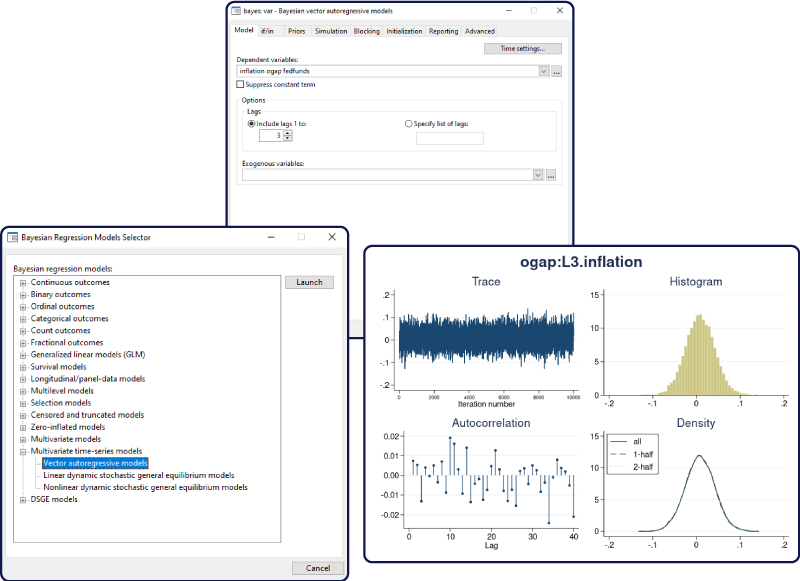
然后,使用bayesfcast进行动态预测;

而脉冲响应函数(IRF)与预测误差方差分解(FEVD)也可类似地得到。
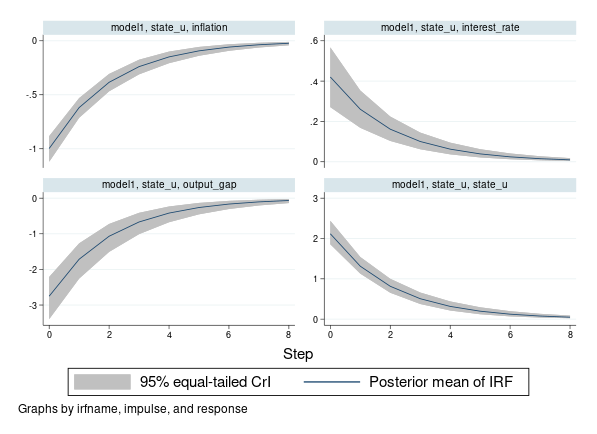
使用贝叶斯方法估计VAR模型有两大好处。首先,VAR模型通常包含较多参数,若样本较小,则估计结果不稳定。而贝叶斯方法由于较易“整合先验信息”(incorporating prior information),故在用小样本估计VAR模型时更为稳健。
其次,经典的VAR模型使用大样本理论进行统计推断与预测,需要假设估计量服从渐近正态分布,在小样本中不易满足。而贝叶斯方法则不使用大样本理论,也无须渐近正态的假设,故更适用于小样本。
贝叶斯多层模型(Bayesian multilevel models)。Stata 17新推出的bayesmh命令可以估计一系列的贝叶斯多层模型,包含“单变量”(univariate)或“多变量”(multivariate)的线性与非线性多层模型(linear and nonlinear multilevel models),乃至面板的生存时间模型(joint longitudinal and survival-time models)以及结构方程之类的模型(SEM-type models)等。
贝叶斯线性与非线性DSGE模型(Bayesian linear and nonlinear DSGE models)。“动态随机一般均衡”(Dynamic Stochastic General Equilibrium,简记DSGE)模型是宏观经济学的主流模型。在Stata 16 中,可使用命令dsge与dsgenl分别估计线性与非线性的 DSGE 模型。
在Stata 17中,只要在命令dsge与dsgenl之前加上前缀bayes,即可估计相应的线性或非线性的贝叶斯DSGE模型。可供用户选用的 “先验分布”(prior distribution)多达30以上,并可进行贝叶斯脉冲响应分析(Bayesian IRF analysis),区间假设检验(interval hypothesis testing),以及使用贝叶斯因子(Bayesian factors)来比较模型等。

有时样本数据中存在分组(比如,分为3组),且这些分组有天然的排序(比如,记为1,2,3组),即所谓 “排序分组”(ordered groups)。在这种排序分组的数据中,经常希望检验某个变量在此分组排序中(比如,第1-3组),是否存在某种趋势,比如此变量的取值倾向于越来越大,即所谓 “tests for trend across ordered group”。
为此,可使用Stata已有命令nptrend,进行非参数的Cuzick秩检验(Cuzick test using ranks)。而Stata 17的最新版nptrend命令,则在 Cuzick秩检验之外,新增了三个非参数检验,即“Cochran-Armitage test”,“Jonckheere-Terpstra test” 与“linear-by-linear trend test”,使得命令nptrend的功能大大增强。
“元分析”(meta-analysis)将多个类似的研究结果综合在一起。比如,针对某个疫苗的有效性(vaccine efficacy),在世界各地进行了多个实验,如何将每个实验所得的疫苗有效性指标,通过加权平均得到统一的度量。Stata 17将Stata的元分析功能作了进一步的提升。
多维元分析(Multivariate meta-analysis)。在将多个研究结果综合在一起时,其中的每个研究可能同时汇报 “多个效应规模”(multiple effect sizes),而这些效应之间可能存在相关性。若使用Stata既有的 meta命令,则会忽略这种相关性。Stata 17的新增命令meta mvregress可进行多维元分析,并处理这种相关性。
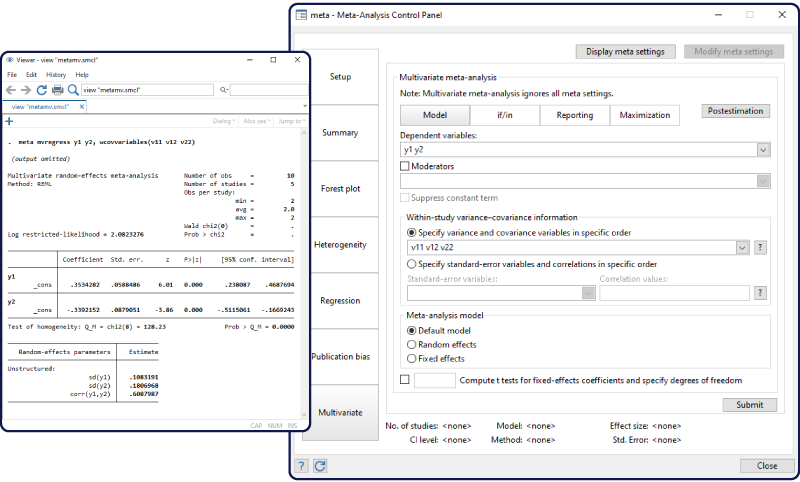
加尔布雷斯图(Galbraith plots)。Stata 17还新增了命令meta galbraithplot,可以画元分析的 “加尔布雷斯图”(Galbraith plots)。此图可用于评估不同研究之间的异质性(assessing heterogeneity of the studies),并发现潜在的极端值(potential outliers)。
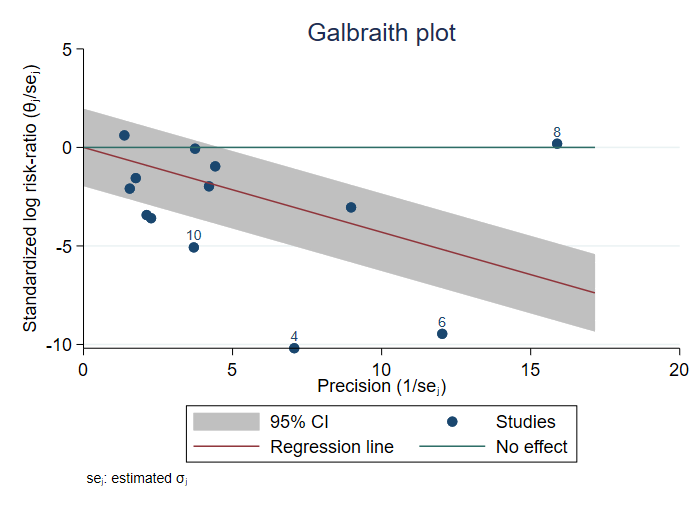
留一元分析(Leave-one-out meta analysis)。Stata 17新增了 “留一元分析”(Leave-one-out meta-analysis)的功能。所谓“留一元分析”,就是在进行元分析时,每次均留出一个研究(不放在样本中),以考察元分析结果的稳健性;比如,最终结果是否过度依赖于某个研究。在使用Stata命令meta summarize或meta forestplot进行元分析时,可使用新增的选择项leaveoneout来进行留一元分析。
在大数据时代,Stata也在加快与主流软件平台的整合,为用户提供更多的增值服务。这在Stata 17的此次升级中体现尤其突出。
与 Python 的整合(Python integration)。Python已是炙手可热的主流计算机语言。为此,Stata 16专门提供了一个与Python的接口,让用户在熟悉的Stata界面下调用Python,并在Stata中显示运行结果。Stata 17则更进一步,推出了新的Python包(Python package)pystata,使得用户可在Python 中方便地调用Stata。Stata 17还引入了一个新概念 “PyStata” ,包括 Stata与Python交互的所有方式。
与 Java 的整合(Java integration)。Java是一种应用广泛的跨平台编程语言。在Stata 17中,你可以十分方便地在Stata程序中嵌入并执行 Java 代码。
对于JDBC数据交换格式的支持(Support for JDBC)。JDBC(Java Database Connectivity)是一个在不同程序与数据库之间交换数据的跨平台标准(a cross-platform standard for exchanging data between programs and databases)。在Stata 17中,通过支持JDBC,使得 Stata用户可从一些最流行的数据库导入数据,包括Oracle、MySQL、AmazonRedShift、Snowflake、Microsoft SQL Server等。
与H2O的整合(H2O integration)。H2O是一款流行的机器学习软件平台。在Stata 17中,你可以连接并调用H2O的机器学习算法。这无疑为Stata用户打开了另外一扇通往机器学习的窗口!
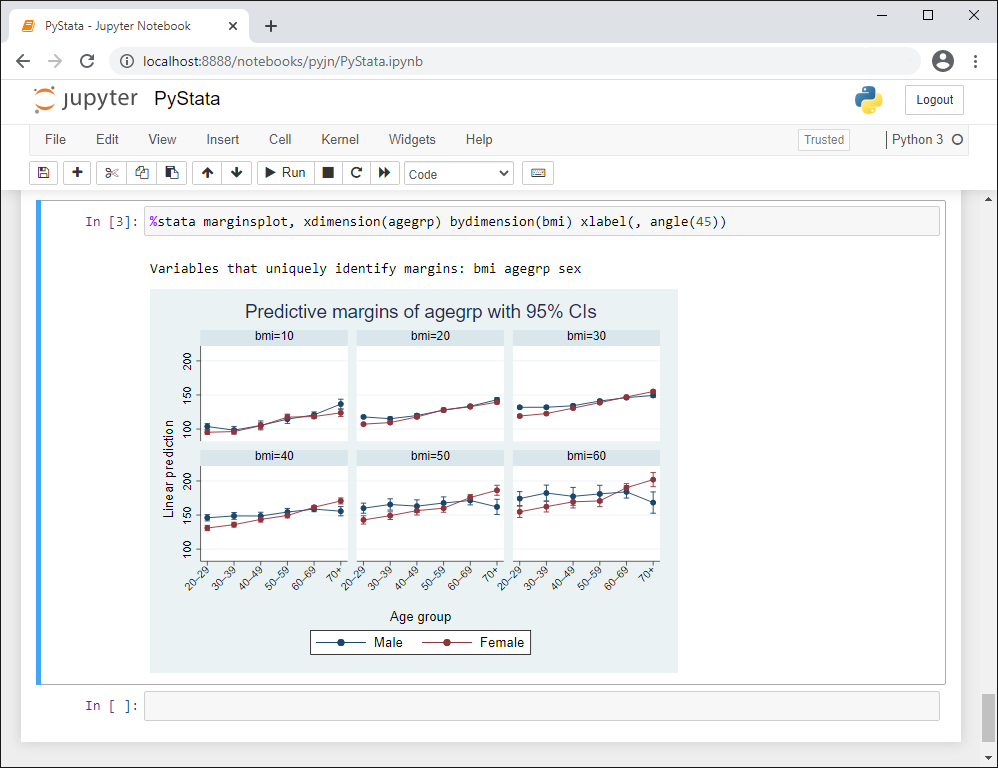
在Jupyter Notebook中使用Stata(Jupyter Notebook with Stata)。Jupyter Notebook是一款基于网页的流行“集成开发环境”(integrated development environment,简记 IDE),尤其方便展示代码、公式、文字与可视化。在Stata 17中,作为PyStata的一部分(依赖于 Python 包 pystata),你可以从 Jupyter Notebook调用 Stata与Mata(Stata的矩阵语言)。这意味着,你可以在同一环境中整合Python与Stata的功能,使得你的工作更加可复制(reproducible)且易于分享。
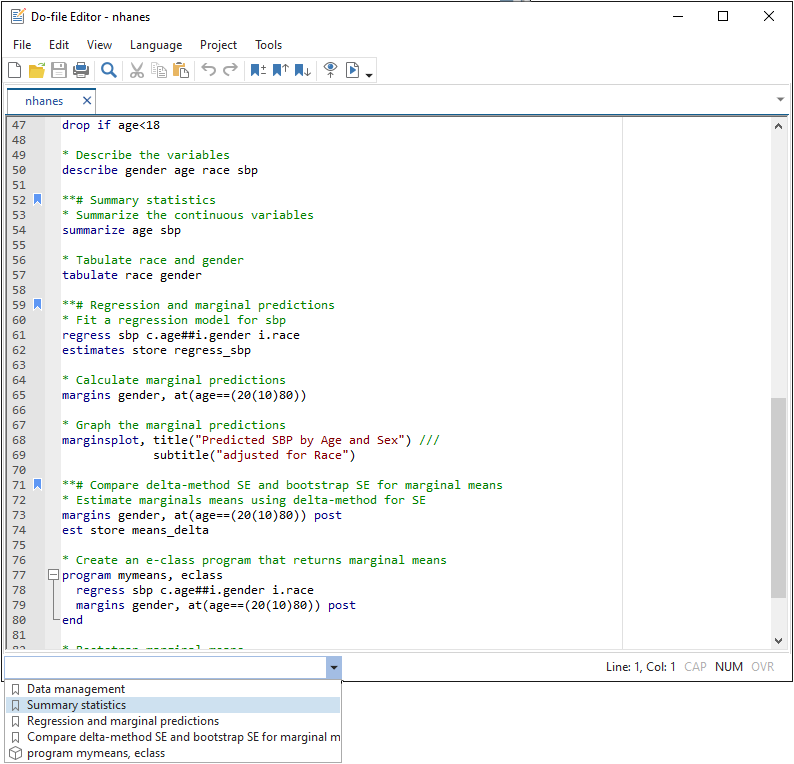
Do文件编辑器的改进(Do-file Editor improvements)。随着编程的重要性日益提高,Stata 16在Do文件编辑器中加入了 “自动填写完成”(autocompletion)与 “语法高亮”(syntax highlighting)的功能。Stata 17又将Do文件编辑器的功能进一步提升。
在Stata 17的Do文件编辑器中,可通过设置 “bookmarks”(书签)而在一个较长的do文件中迅速跳至想要编辑的部分。Stata 17的Do文件编辑器还新增了“navigation control”(导航),其中罗列所有的书签及其标签(bookmarks and their labels),以该Do文件中的全部“程序”(programs)。
Stata的速度提升(Faster Stata)。在大数据时代,基础算法的速度越来越重要。为此,Stata 17更新了命令sort与collapse的算法,使之更为快捷。另外,Stata 17也提升了命令mixed(用于估计多层混合效应模型,即 multilevel mixed-effects models)的运行速度。
使用Intel Math Kernel Library(MKL)提升速度。Stata 17引入了Intel Math Kernel Library(MKL),适用于所有Intel或AMD的64位计算机,从而可调用深度优化(deeply optimized)的LAPACK(Linear Algebra PACKage)线性代数包。这将使得Stata与Mata的底层计算速度进一步提升,而Stata用户无须作任何事情即可享用。
处理日期与时间的新函数(New functions for dates and times)。Stata 17 引入了方便处理日期与时间的新函数,包括Datetime duration(计算持续时间),Datetime relative dates(计算相对日期,比如下个生日的日期),以及Datetime(从日期中提取不同的成分)。这些新函数还会自动考虑闰年(leap years)、闰日(leap days)与闰秒(leap seconds)的因素。

总之,Stata 17是一次令人激动的重大升级,不仅有贝叶斯计量经济学的高歌猛进,与主流计算机语言平台的深度整合,更便于编程的Do文件编辑器,而且更为贴近计量实战的需求(DID,表格输出,离散选择等)。显然,在可预见的将来,Stata 依然会是经管社科的首选计量与统计软件。

快!精准!易于使用! Stata是一个完整的集成软件包,可提供您的所有数据科学需求 - 数据处理,可视化,统计和自动报告。

Stata的数据管理功能如下:
进出口
ODBC,SQL
排序,匹配,合并,加入,追加,创建
内置电子表格
unicode
处理文本或二进制数据
在本地或在Web上访问数据
收集组间的统计信息
BLOBs -strings可以容纳整个文档
数十亿个观测值
成千上万的变数
生存数据, 面板数据, 多级数据, 调查数据, 多重插补数据, 分类数据, 时间序列数据
更重要的是,支持您的所有数据科学需求。







Stata可以轻松生成出版品质,风格独特的图形。
可以指向并单击以创建自定义图形。或者,编写脚本以可重现的方式生成数百或数千个图形。将图形导出为EPS或TIFF以供发布,将PNG或SVG导出为Web,或导出为PDF以供查看。使用集成的图形编辑器,可以单击以更改有关图形的任何内容,或添加标题,注释,线条,箭头和文本。

自动报告结果所需的所有工具 。
动态Markdown文档
创建Word文档
创建PDF文档
创建Excel文件
图形方案
Word,HTML,PDF,SVG,PNG
很多人谈论可重复的研究。
Stata已经致力于它超过30年。
我们不断添加新功能; 我们甚至从根本上改变了语言元素。不管。Stata是唯一具有集成版本控制的统计软件包。如果你在1985年编写了一个脚本来执行分析,那么同样的脚本仍然可以运行,并且今天仍会产生相同的结果。您在1985年创建的任何数据集,今天都可以阅读。在2050年也是如此.Stata将能够运行你今天所做的任何事情。
我们认真对待再现性。
我们不只是编程统计方法,我们验证它们。
您从Stata估算器中看到的结果依赖于与其他估算器的比较,蒙特卡罗模拟的一致性和覆盖范围,以及我们的统计人员进行的大量测试。我们发运的每个Stata都通过了一个认证套件 ,其中包括320万行测试代码,可生成490万行输出。我们对490万行输出中的每个数字和文本进行认证。


我们的每个数据管理功能都经过充分解释和记录,并在实际示例中显示。每个估算器都有完整的文档记录,包括几个关于实际数据的示例,以及如何解释结果的真实讨论。这些示例为您提供数据,以便您可以在Stata中工作甚至扩展分析。我们为您提供每个功能的快速入门,展示一些最常见的用途。想要更多细节?我们的方法和公式部分提供了计算内容的具体信息,我们的参考文献为您提供了更多信息。 Stata是一个很大的包,所以有很多文档 - 超过15,000页,共31卷。但不要担心,键入帮助 我的主题,Stata将搜索其关键字,索引,甚至社区提供的包,为您带来您需要了解的主题。一切都在Stata内可用。
Stata的所有功能都可以通过 菜单,对话框,控制面板,数据编辑器,变量管理器,图形编辑器甚至SEM 图形生成器来访问。您可以通过任何分析指向并单击您的方式。
如果您不想编写命令和脚本,则不必这样做。
即使您指向并单击,也可以记录所有结果,然后将其包含在报告中。您甚至可以保存您的操作创建的命令,并在以后重现您的完整分析。

Stata执行任务的命令直观且易于学习。更好的是,您学习执行任务的所有内容都可以应用于其他任务。例如,您只需将性别==“女性”添加到任何命令,以限制您对样本中的女性进行分析。您只需将vce(robust)添加到任何估算器中,以获得对许多常见假设都很稳健的标准误差和假设检验。
一致性甚至更深。您对数据管理命令的了解通常适用于估算命令,反之亦然。还有一整套postestimation命令来执行假设检验,形成线性和非线性组合,进行预测,形成对比,甚至用交互图进行边际分析。在几乎每个估算器之后,这些命令的工作方式相同。
排序命令来读取和清理数据,然后执行统计测试和估计,最后报告结果是可重复研究的核心。Stata使所有研究人员都可以访问此过程。
每个人都有他们一直在做的任务 - 创建特定类型的变量,生成特定的表,执行一系列统计步骤,计算RMSE等。可能性是无穷无尽的。Stata有数千个内置程序,但可能拥有相对独特的任务或者您希望以特定方式完成的任务。
如果您编写了一个脚本来执行给定数据集上的任务,则可以轻松地将该脚本转换为可用于所有数据集,任何变量集以及任何观察集的内容。
自动化的一些内容可能非常实用。只需一点代码,就可以将自动化脚本转换为Stata命令。支持Stata官方命令支持的标准功能的命令。可以与使用官方命令相同的方式使用的命令。

 Stata还包括一种高级编程语言-Mata。
Stata还包括一种高级编程语言-Mata。
Mata具有您期望在编程语言中使用的结构,指针和类,并为矩阵编程添加了直接支持。
Mata既是一个用于操作矩阵的交互式环境,也是一个可以生成编译和优化代码的完整开发环境。它包括处理面板数据的特殊功能,对实际或复杂矩阵执行操作,为面向对象编程提供全面支持,并与Stata的各个方面完全集成。
Stata/MP, Stata/SE, Stata/BE 三个版本
Stata/MP : 最快的Stata版本(四核,双核和多核/多处理器计算机),可以分析最大的数据集。
Stata/SE : 标准版; 对于更大的数据集。
Stata/BE : 基础版; 用于中型数据集。
| Product features |

|
 |
 |
2.14 billion | 2.14 billion | Up to 20 billion | ||||||||
|
798 | 10,998 | 65,532 | |||||||||||
Time to run logistic regression with 5 million obs and 10 covariates |
|
|
|
|||||||||||
|
 |
|
|
|||||||||||
|
|
|
|
|||||||||||
|
|
|
|
|||||||||||
|
|
|
|
|||||||||||
|
|
|
|
|||||||||||
|
|
|
|
|||||||||||
|
|
|
|
|||||||||||
|
|
|
|
|
点击列表链接查看视频功能演示 |
|
|
Lasso|套索估计量 Reproducible reporting|研究报告的可重复性 Meta-Analysis|元分析 Choice Models|选择模型 Python Integration|Python集成 Bayes—multiple chains, more|贝叶斯分析新功能 Panel-data ERMs|面板数据ERM Import Data from SAS and SPSS |从SAS和SPSS导入数据 Nonparametric series regression |非参数序列回归 Frames — multiple datasets in memory|帧-内存中的多个数据集 Sample-size analysis for CIs Panel-data mixed logit | 面板数据 |
Nonlinear DSGE models|非线性 DSGE 模型 Multiple-group IRT | 多组IRT xtheckman|xtheckman新命令 NLMEMs with lags: PK models | PK模型 Heteroskedastic ordered probit | 异方差有序概率 Point sizes for graphics | 图形 Numerical integration Linear programming | 线性回归 Stata in Korean | 韩语版Stata Mac interface | Mac介面 Do-file Editor autocompletion |do 文件编辑器 |
Stata 的统计功能十分强大,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如 Cox 比例风险回归,指数与 Weibull 回归,多类结果与有序结果的 logistic 回归, Poisson 回归,负二项回归及广义负二项回归,随机效应模型等。Stata 具有如下详细的统计分析能力:
| 统计分析能力 | 能力介绍 |
| 数值变量资料的一般分析 | 参数估计,t检验,单因素和多因素的方差分析,协方差分析,交互效应模型,平衡和非平衡设计,嵌套设计,随机效应,多个均数的两两比较,缺项数据的处理,方差齐性检验,正态性检验,变量变换等。 |
| 分类资料的一般分析 | 参数估计,列联表分析 ( 列联系数,确切概率 ) ,流行病学表格分析等。 |
| 等级资料的一般分析 | 秩变换,秩和检验,秩相关等。 |
| 相关与回归分析 | 简单相关,偏相关,典型相关,以及多达数十种的回归分析方法,如多元线性回归,逐步回归,加权回归,稳键回归,二阶段回归,百分位数 ( 中位数 ) 回归,残差分析、强影响点分析,曲线拟合,随机效应的线性回归模型等。 |
| 其他方法 | 质量控制,整群抽样的设计效率,诊断试验评价, kappa 等。 |
这些图形的巧妙应用,可以满足绝大多数用户的统计作图要求。在有些非绘图命令中,也提供了专门绘制某种图形的功能,如在生存分析中,提供了绘制生存曲线图,回归分析中提供了残差图等。
三、矩阵运算功能
矩阵代数是多元统计分析的重要工具, Stata 提供了多元统计分析中所需的矩阵基本运算,如矩阵的加、积、逆、 Cholesky 分解、 Kronecker 内积等;还提供了一些高级运算,如特征根、特征向量、奇异值分解等;在执行完某些统计分析命令后,还提供了一些系统矩阵,如估计系数向量、估计系数的协方差矩阵等。
四、程序设计功能
Stata 是一个统计分析软件,但它也具有很强的程序语言功能,这给用户提供了一个广阔的开发应用的天地,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。Stata 的 ado 文件 ( 高级统计部分 ) 是用 Stata 自己的语言编写的。
Stata 其统计分析能力远远超过了 SPSS ,在许多方面也超过了 SAS 。由于 Stata 在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此计算速度极快(一般来说, SAS 的运算速度要比 SPSS 至少快一个数量级,而 Stata 的某些模块和执行同样功能的 SAS 模块比,其速度又比 SAS 快将近一个数量级。) Stata 也是采用命令行方式来操作,但使用上远比 SAS 简单。其生存数据分析、纵向数据(重复测量数据)分析等模块的功能甚至超过了 SAS 。用 Stata 绘制的统计图形相当精美,很有特色。
| 功能名称 | 功能介绍 |
|
线性模型 (Linear models) |
regression • censored outcomes • endogenous regressors • bootstrap, jackknife, and robust and cluster–robust variance • instrumental variables • three-stage least squares • constraints • quantile regression • GLS • more |
|
面板/纵向数据 (Panel/longitudinal data) |
random and fixed effects with robust standard errors • linear mixed models • random-effects probit • GEE • random- and fixed-effects Poisson • dynamic panel-data models • instrumental variables • panel unit-root tests • more |
|
多级混合效应模型 (Multilevel mixed-effects models) |
continuous, binary, count, and survival outcomes • two-, three-, and higher-level models • generalized linear models • nonlinear models • random intercepts • random slopes • crossed random effects • BLUPs of effects and fitted values • hierarchical models • residual error structures • DDF adjustments • support for survey data • more |
|
二进制、计数和有限结果 (Binary, count, and limited outcomes) |
logistic, probit, tobit • Poisson and negative binomial • conditional, multinomial, nested, ordered, rank-ordered, and stereotype logistic • multinomial probit • zero-inflated and left-truncated count models • selection models • marginal effects • more |
|
扩展回归模型(ERMs) (Extended regression models (ERMs)) |
combine endogenous covariates, sample selection, and nonrandom treatment in models for continuous, interval-censored, binary, and ordinal outcomes • more |
|
广义线性模型(GLMs) (Generalized linear models (GLMs)) |
ten link functions • user-defined links • seven distributions • ML and IRLS estimation • nine variance estimators • seven residuals • more |
|
有限混合模型(FMMs) (Finite mixture models (FMMs)) |
fmm: prefix for 17 estimators • mixtures of a single estimator • mixtures combining multiple estimators or distributions • continuous, binary, count, ordinal, categorical, censored, truncated, and survival outcomes • more |
|
空间自回归模型 (Spatial autoregressive models) |
spatial lags of dependent variable, independent variables, and autoregressive errors • fixed and random effects in panel data • endogenous covariates • analyze spillover effects • more |
|
方差分析/多变量方差分析 (ANOVA/MANOVA) |
balanced and unbalanced designs • factorial, nested, and mixed designs • repeated measures • marginal means • contrasts • more |
|
精确统计 (Exact statistics) |
exact logistic and Poisson regression • exact case–control statistics • binomial tests • Fisher’s exact test for r × c tables • more |
|
线性动态随机一般均衡模型 (Linearized DSGE models) |
specify models algebraically • solve models • estimate parameters • identification diagnostics • policy and transition matrices • IRFs • dynamic forecasts • more |
|
测试、预测和结果 (Tests, predictions, and effects) |
Wald tests • LR tests • linear and nonlinear combinations • predictions and generalized predictions • marginal means • least-squares means • adjusted means • marginal and partial effects • forecast models • Hausman tests • more |
|
差异、成对比较和差数 (Contrasts, pairwise comparisons, and margins) |
compare means, intercepts, or slopes • compare with reference category, adjacent category, grand mean, etc. • orthogonal polynomials • multiple-comparison adjustments • graph estimated means and contrasts • interaction plots • more |
|
简单最大概似法 (Simple maximum likelihood) |
specify likelihood using simple expressions • no programming required • survey data • standard, robust, bootstrap, and jackknife SEs • matrix estimators • more |
|
可编程最大概似法 (Programmable maximum likelihood) |
user-specified functions • NR, DFP, BFGS, BHHH • OIM, OPG, robust, bootstrap, and jackknife SEs • Wald tests • survey data • numeric or analytic derivatives • more |
|
再抽样及模拟方法 (Resampling and simulation methods) |
bootstrap • jackknife • Monte Carlo simulation • permutation tests • more |
|
时间序列 (Time series) |
ARIMA • ARFIMA • ARCH/GARCH • VAR • VECM • multivariate GARCH • unobserved-components model • dynamic factors • state-space models • Markov-switching models • business calendars • tests for structural breaks • threshold regression • forecasts • impulse–response functions • unit-root tests • filters and smoothers • rolling and recursive estimation • more |
|
生存分析 (Survival analysis) |
Kaplan–Meier and Nelson–Aalen estimators, • Cox regression (frailty) • parametric models (frailty, random effects) • competing risks • hazards • time-varying covariates • left-, right-, and interval-censoring • Weibull, exponential, and Gompertz models • more |
|
贝叶斯分析 (Bayesian analysis) |
thousands of built-in models • univariate and multivariate models • linear and nonlinear models • multilevel models • continuous, binary, ordinal, and count outcomes • bayes: prefix for 45 estimation commands • continuous univariate, multivariate, and discrete priors • add your own models • convergence diagnostics • posterior summaries • hypothesis testing • model comparison • more |
|
功效和样本大小 (Power and sample size) |
power • sample size • effect size • minimum detectable effect • means • proportions • variances • correlations • ANOVA • regression • cluster randomized designs • case–control studies • cohort studies • contingency tables • survival analysis • balanced or unbalanced designs • results in tables or graphs • more |
|
治疗效果/因果推断 (Treatment effects/Causal inference) |
inverse probability weight (IPW) • doubly robust methods • propensity-score matching • regression adjustment • covariate matching • multilevel treatments • endogenous treatments • average treatment effects (ATEs) • ATEs on the treated (ATETs) • potential-outcome means (POMs) • continuous, binary, count, fractional, and survival outcomes • more |
|
结构方程模型(SEM) (SEM (structural equation modeling)) |
graphical path diagram builder • standardized and unstandardized estimates • modification indices • direct and indirect effects • continuous, binary, count, ordinal, and survival outcomes • multilevel models • random slopes and intercepts • factor scores, empirical Bayes, and other predictions • groups and tests of invariance • goodness of fit • handles MAR data by FIML • correlated data • survey data • more |
|
潜伏组分析 (Latent class analysis) |
binary, ordinal, continuous, count, categorical, fractional, and survival items • add covariates to model class membership • combine with SEM path models • expected class proportions • goodness of fit • predictions of class membership • more |
|
多重估算 (Multiple imputation) |
nine univariate imputation methods • multivariate normal imputation • chained equations • explore pattern of missingness • manage imputed datasets • fit model and pool results • transform parameters • joint tests of parameter estimates • predictions • more |
|
调查方法 (Survey methods) |
multistage designs • bootstrap, BRR, jackknife, linearized, and SDR variance estimation • poststratification • DEFF • predictive margins • means, proportions, ratios, totals • summary tables • almost all estimators supported • more |
|
聚类分析 (Cluster analysis) |
hierarchical clustering • kmeans and kmedian nonhierarchical clustering • dendrograms • stopping rules • user-extensible analyses • more |
|
项目反应理论(IRT) (IRT (item response theory)) |
binary (1PL, 2PL, 3PL), ordinal, and categorical response models • item characteristic curves • test characteristic curves • item information functions • test information functions • differential item functioning (DIF) • more |
|
多变量方法 (Multivariate methods) |
factor analysis • principal components • discriminant analysis • rotation • multidimensional scaling • Procrustean analysis • correspondence analysis • biplots • dendrograms • user-extensible analyses • more |
|
数据[资料]管理 (Data management) |
data transformations • match-merge • import/export data • ODBC • SQL • Unicode • by-group processing • append files • sort • row–column transposition • labeling • save results • more |
|
绘图 (Graphics) |
lines • bars • areas • ranges • contours • confidence intervals • interaction plots • survival plots • publication quality • customize anything • Graph Editor • more |
|
图形用户界面 (Graphical user interface) |
menus and dialogs for all features • Data Editor • Variables Manager • Graph Editor • Project Manager • Do-file Editor • Clipboard Preview Tool • multiple preference sets • more |
|
参考资料 (Documentation) |
31 manuals • 15,000+ pages • seamless navigation • thousands of worked examples • quick starts • methods and formulas • references • more |
|
基本统计 (Basic statistics) |
summaries • cross-tabulations • correlations • z and t tests • equality-of-variance tests • tests of proportions • confidence intervals • factor variables • more |
|
非参数方法 (Nonparametric methods) |
nonparametric regression • Wilcoxon–Mann–Whitney, Wilcoxon signed ranks, and Kruskal–Wallis tests • Spearman and Kendall correlations • Kolmogorov–Smirnov tests • exact binomial CIs • survival data • ROC analysis • smoothing • bootstrapping • more |
|
流行病学 (Epidemiology) |
standardization of rates • case–control • cohort • matched case–control • Mantel–Haenszel • pharmacokinetics • ROC analysis • ICD-10 • more |
|
GMM与非线性回归 (GMM and nonlinear regression) |
generalized method of moments (GMM) • nonlinear regression • more |
|
其他统计方法 (Other statistical methods) |
kappa measure of interrater agreement • Cronbach's alpha • stepwise regression • tests of normality • more |
|
函数 (Functions) |
statistical • random-number • mathematical • string • date and time • more |
|
互联网功能 (Internet capabilities) |
ability to install new commands • web updating • web file sharing • latest Stata news • more |
|
社区编写的命令 (community-contributed commands) |
community-contributed commands for meta-analysis, data management, survival, econometrics, more |
|
编程特点 (Programming features) |
adding new commands • command scripting • object-oriented programming • menu and dialog-box programming • dynamic documents • Markdown • Project Manager • plugins • more |
|
矩阵编程-Mata (Matrix programming—Mata) |
interactive sessions • large-scale development projects • optimization • matrix inversions • decompositions • eigenvalues and eigenvectors • LAPACK engine • real and complex numbers • string matrices • interface to Stata datasets and matrices • numerical derivatives • object-oriented programming • more |
|
嵌入式统计计算 (Embedded statistical computations) |
Numerics by Stata |
作为大数据Volume的一种重要形式,“高维数据”(high-dimensional data)解释变量很多,甚至超过样本容量。Lasso (Least Absolute Shrinkage and Selection Operator,也称“套索估计量”)及其衍生的系列估计量正是进行高维回归的主要工具。
Lasso系列的官方命令,包括lasso, elasticnet(弹性网)与 sqrtlasso(平方根Lasso),可估计线性回归模型(比如 lasso linear)、二值选择模型(比如,lasso logit 与 lasso probit)、计数模型(比如,lasso poisson)等。
Lasso 系列的估计量通常使用惩罚回归(penalized regressions)来处理高维数据,以避免“过拟合”(overfit)与“方差爆炸”(variance explosion),并进行“变量选择”(variable selection)。这些惩罚回归对于回归系数过大的惩罚力度则一般由调节参数(tuning parameter)或 L1范数(L1 norm)来控制。
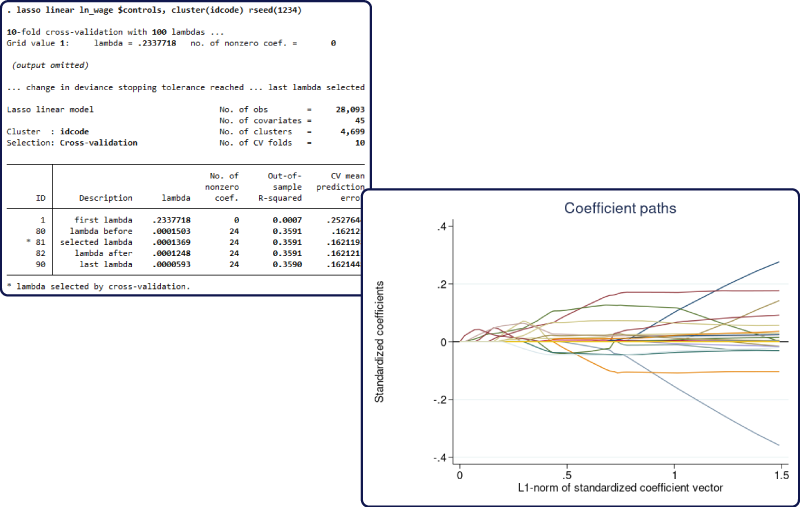
使用 Stata 16的Lasso命令,可以很方便地计算回归系数的整个路径(coefficient paths),作为调节参数 或 L1范数的函数;并根据“交叉验证”(cross-validation)选择最优的调节参数 ,参见下图。


Stata 官方命令还提供了 Lasso 系列相应的统计推断方法,比如计算标准误、置信区间,或进行假设检验。这些统计推断方法包括“double-selection lasso”(比如,dsregress,dslogit,dspoisson),“partialling-out lasso”(比如,poregress,pologit,popoisson),以及“cross-fit partialing out lasso”(比如,xporegress,xpologit,xpopoisson)。
在大数据时代,学界与业界越来越需要在内存中同时处理多个数据集。在此前的 Stata 版本中,Stata 内存只能有一个数据集。这种设置虽简便易行,在小数据时代也基本够用,但在大数据时代,由于数据的来源 Variety 多样,已成为应用的瓶颈。
因此,Stata 适时地推出在内存内同时调用多达100个数据集的重要功能。比如,你可以很方便地根据内存中多个数据集的信息来定义一个新的变量。

随着机器学习与数据科学的兴起,Python 无疑是最炙手可热的编程语言之一。为此,Stata 16 专门提供了一个与 Python 的接口,让用户可以在熟悉的 Stata 界面下调用 Python,并在 Stata 中显示运行结果。
比如,此前的 Stata 版本无法画三维立体图,而在Stata 16中,通过调用Python 的 Matplotlib 则不难实现(参见下图)。

这也意味着,你可以在 Stata 中,通过 Python 接口,使用 Python 所擅长的各种机器学习方法,包括随机森林、梯度提升、支持向量机、神经网络等!
在大数据时代,编程越来越成为一种基本技能。在 Stata 中编程,无疑需要一个很好的 do 文件编辑器(Do-file Editor)。 让人惊喜的是,Stata 的 do 文件编辑器的性能也有了大幅提升,包括 Stata 命令的自动填写完成(autocompletion),以及更多语法高亮显示(syntax highlighting),这无疑将为 Stata 编程提供很大便利。

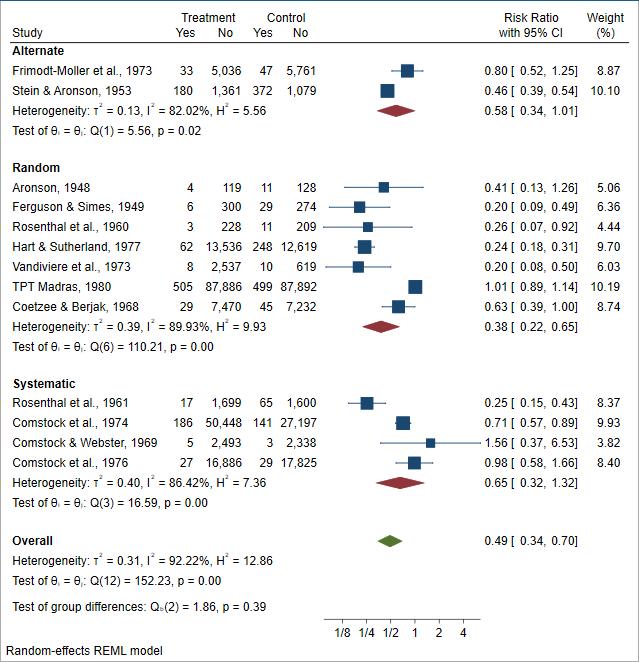
Stata 提供了全新的 Meta-Analysis 模块,使得元分析变得十分方便、快捷而高效,并辅之以强大的可视化功能(参见下图)。

由于大数据的更新频繁特点(Velocity),使得数据分析经常需要重复进行,使用更新的数据。此时,研究报告的可重复性(Reproducibility)就变得日益重要,即保证任何人只要运行你的 Stata 程序即可得到完全一样的研究报告。这些研究报告的格式可以是 Word,PDF,Excel 或 HTML(参见下图)。 随着大数据时代的数据来源 Variety 越来越多,使得我们时常需要将不同来源的样本数据之研究结果整合在一起,即所谓“元分析”(Meta-Analysis)。

而且,当你的数据集更新之后,再运行一遍你的 Stata,则你的研究报告也会相应地自动更新!Stata 16 新引入或完善的相关命令包括 dyndoc,markdown,putdocx,html2docx,doc2pdf。
小贴士:还在发愁如何将 Word 文件转化为 PDF 格式?Stata 16 的 doc2pdf 命令就能帮你搞定!
如果你有数据在 SAS 或 SPSS 中,想要导入 Stata 以利用其强大的统计与计量功能,Stata 16 贴心地提供了专门的新命令 import sas 与 import spss,使得这种数据迁移变得十分方便与快捷,参见下图。


序列回归(series regression)是非参数回归(nonparametric regression)的一种重要方法。它使用多项式(polynomials)、B-样条(B-splines)或样条(splines)所构成的序列来近似逼近任意的未知回归函数。
Stata 推出的命令 npregress series 填补了 Stata 在非参数回归领域的又一空白,使得非参数序列回归变得方便而高效;比如,计算平均边际效应(average marginal effects)。命令 npregress series 甚至可以估计“半参数模型”(semi-parametric model),即同时包含参数与非参数部分的模型。
对于微观计量中常用的“离散选择模型”(discrete choice models),Stata 设立了一个“选择模型”(Choice Models)的模块。在估计选择模型之前,你先通过命令 cmset 来宣布你的数据为选择模型,然后可用命令 cmsummarize,cmchoiceset,cmtab 或 cmsample 来考察你的选择模型。
估计选择模型的相应 Stata 命令也统一带上了 cm 的前缀,比如
cmclogit:conditional logit model
cmmixlogit:mixed logit model
cmxtmixlogit:panel-data mixed logitmodel
cmmprobit:multinomial probitmodel
cmroprobit:rank-ordered probitmodel
cmrologit:rank-ordered logitmodel
其中,cmxtmixlogit 是 Stata 16的全新命令,用于估计面板数据的混合逻辑模型(mixed logit models for panel data)。
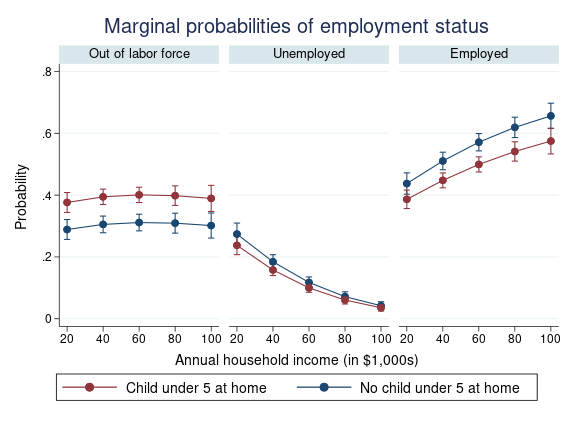
Stata 15 推出了 ERM(Extended Regression Models)模块,可以处理同时出现“内生性”(endogeneity)、“样本选择”(sample selection)与“处理效应”(treatment)这三种并发症的情形,或三者的任意组合,非常灵活实用。Stata 16 则将ERMs 推广到了面板数据中,新引入了xtegress,xteintreg,xteprobit,xteoprobit 等强大命令。
Stata 的“贝叶斯分析”(Bayesian Analysis)模块也有了不少新功能。比如,可使用多个马尔科夫链(multiple chains)来检验现代贝叶斯分析所依赖的马尔科夫链蒙特卡洛(Markov China Monte Carlo)是否收敛;以及使用后验分布(posterior distribution)进行“贝叶斯预测”(Bayesian predictions),参见下图。

tata 可以通过命令 dsgenl 来估计非线性 DSGE 模型。 使用命令dsgenl,无须再手工将 DSGE 模型线性化,直接输入非线性的 DSGE 模型,Stata 即会自动地对它进行线性化与估计。
xtheckman命令 使得 Heckman 的样本选择模型(sample model)也可以在面板数据中估计。
系统要求
Stata for Windows
Windows 10 *
Windows 8 *
Windows Server 2019, 2016, 2012, 2008 R2 *
* Stata requires 64-bit Windows for x86-64 processors made by Intel® or AMD
Stata for Mac
Mac with Intel processor or Apple Silicon
macOS 10.11 (El Capitan) or newer for Macs with Intel processors and macOS 11.0 (Big Sur) or newer for Macs with Apple Silicon
Stata for Linux
Any 64-bit (x86-64 or compatible) running Linux
For xstata, you need to have GTK 2.24 installed
Hardware requirements
| Package | Memory | Disk space |
| Stata/MP | 4GB | 1GB |
| Stata/SE | 2GB | 1GB |
| Stata/BE | 1GB | 1GB |
在在世界已迈入大数据新时代的今天,Stata在高校商科类专业、科研院所以及企业界的应用越来越广泛,已成为各大高校必备的专业软件,随着其用户群体的不断扩大,建立中国用户与Stata总部之间的沟通和磋商机制越发成熟。聆听用户的心声,收集业界专家的论点与建议,已成为会议的主旨,无论您是为科研应用之路寻找最佳解决方案, 还是专注Stata软件探索与研究,抑或是竭力于提高工作效率的数据处理技能,在Stata中国用户大会上,您的需求都能得到前所未有的碰撞与共鸣。故Stata中国用户大会(China Stata Users' Conference)由此诞生,由北京友万信息科技有限公司(Beijing Uone Info&Tech Co.,Ltd)和StataCorp LLC原厂联合发起,规划每年举办一届,通过广泛的国际学术交流,帮助Stata中国用户探索更深层次的理论和研究。我们希望通过每年一届的Stata用户会议,让Stata中国用户及学者提高自身软件应用水平,开辟“学中用、用中学”的创新学习模式,打造强有力的学术氛围,帮助中国用户建立完善的软件技术服务体系,形成中国用户之间的技术、经验交流平台。
2017-2020 China Stata Users' Conference 大会资源免费奉送,关注Stata的小伙半们抓紧时间领取咯!
2020年随着新冠疫情的蔓延,全球都投入到积极防控的大潮中,如何高效获取和处理COVID-19数据,必然成为本届会议的热点主题 。第四届“Stata中国用户大会”(China Stata Users' Conference) 将以“新应用+智交互”为主题,力邀国内外行业领袖及学术专家,共同开启全新主题单元。本次会议以线上直播的方式与大家见面,知识碰撞、经验交流、共享Stata应用新思路。
| 演讲主题 | 演讲人 |
| 《使用Stata获取与处理COVID-19数据》 | 彭 华 StataCorp LLC |
| 《Call Stata from Python》 | 徐 朝 StataCorp LLC |
| 《混频回归方法与Stata应用》 | 王群勇 南开大学 |
| 《基于Stata模拟的内生性来源及其应对》 | 陈传波 中国人民大学 |
| 《跨度回归、偏度回归与峰度回归及Stata应用》 | 陈 强 山东大学 |
| 《平滑转换模型与Stata应用》 | 王群勇 南开大学 |
| 《Causal Mediation》 | 金承刚 北京师范大学 |
| 《合成控制法安慰剂检验改进研究——基于标准化处理效应和非拒绝域的统计推断》 | 连玉君 中山大学 |
| 《Measuring technical efficiency and total factor productivity change with undesirable outputs in Stata》 | 王道平 上海财经大学 |
第三届 Stata 中国用户大会暨“机器学习与计量方法应用研讨会”于2019年8月20—21日在上海财经大学盛大召开并取得圆满成功。会议得到了国内外专家学者及众多用户代表的一致肯定,同时今年也是Stata 16发布年,在会议上我们也希望能够更多的了解对新版本的认知,反映中国用户在应用软件过程中遇到的问题。通过广泛的国际交流,帮助Stata中国用户探索更深层次的理论和研究。
| 演讲主题 | 演讲人 |
| 《Introduction of latest reporting and language extension features in Stata》 | 彭 华 StataCorp LLC |
| 《Stata在公司投融资研究中的应用》 | 覃家琦 南开大学 |
| 《分位数回归:横截面、面板与工具变量法》 | 陈 强 山东大学 |
| 《Inference after lasso model selection》 | 刘 迪 StataCorp LLC |
| 《非参数计量经济方法(核回归,局部线性回归)》 | 王群勇 南开大学 |
| 《Fixed effect panel threshold model for unbalanced panel》 | 王群勇 南开大学 |
| 《Stata在外汇市场实证中的应用》 | 丁剑平 上海财经大学 |
| 《人工智能+ Stata》 | 陈堰平 微软中国 |
2018年“第二届Stata中国用户大会”(2018China Stata Users' Conference)是由北京友万信息科技有限公司(简称:友万科技)主办,顺德职业技术学院承办的聚焦Stata应用与技术落地的盛会。会议核心内容将围绕计量经济方法及应用方向展开广泛的国际学术交流,内容覆盖经济学、金融学、会计学、计算语言学、新闻学、政治学、历史学、医药卫生等微观和宏观计量分析的热门应用领域。今年大会的主题是“Econometric Analysis Method and Application” 秉承“开放协作、技术共享”的宗旨,面对面真诚聆听用户的声音。致力于为业界带来最新技术、行业应用案例展示与最佳实践单元。
会议主题:Econometric Analysis Method and Application
| 演讲主题 | 演讲人 |
| 《大数据、高维回归与Stata》 | 陈 强 山东大学 |
| 《Spatial autoregressive models using Stata》 | 刘 迪 StataCorp LLC |
| 《政策评估与因果推断:Stata应用概述》 | 王群勇 南开大学 |
| 《断点回归》 | 连玉君 中山大学 |
| 《回归分析集成输出解决方案》 | 李春涛 华中科技大学 |
| 《内含资本成本的计算》 | 顾 俊 深圳大学 |
| 《样本选择问题与处理》 | 王群勇 南开大学 |
| 《DSGE在Stata中的应用》 | 许文立 安徽大学 |
| 《Report generation with putdocx, putexcel, putpdf, and dyndoc》 | 彭 华 StataCorp LLC |
2017年“第一届Stata中国用户大会”(2017China Stata Users' Conference)是由北京友万信息科技有限公司和爬虫俱乐部,联合StataCorp LLC发起第一届Stata中国用户大会。首届Stata用户会议的宗旨是“沟通和合作”,我们希望通过定期举办Stata用户会议,形成中国用户之间的技术、经验交流平台;建立和Stata原厂的沟通机制,反映中国用户遇到的问题,让未来的Stata版本更多地反映中国用户的愿望;建立学界与企业界之间的沟通和联系,让Stata用户有更多的机会服务于企业界;打造数据分析领域的高端智库,服务于我国的大数据事业。
会议主题:Retrieving data from website, Cloud oriented empirical analysis, Using Chinese in Stata
| 演讲主题 | 演讲人 |
| 《Stata 15 新版本发布及新功能研讨》 | 彭 华 StataCorp LP 软件工程总监 |
| 《内生性问题:方法及进展》 | 连玉君 中山大学 |
| 《putdocx与格式化输出》 | 李春涛 中南财经政法大学 |
| 《unicode与中文编码》 | 彭 华 StataCorp LP 软件工程总监 |
| 《Stata函数》 | 彭 华 StataCorp LP 软件工程总监 |
| 《Subinfile,网页源代码分析的神器》 | 薛 原 爬虫俱乐部 |
| 《Stata自动化报告与可重复研究》 | 陈堰平 雪晴数据网 |
| 《分词与情感分析》 | 薛 原 爬虫俱乐部 |
| 《文本分析在量化文史学研究中的应用—以<唐书>与<红楼梦>为例》 | 俞俊利 上海交通大学 |
| 《Stata、cURL交互与网络爬虫:以微博API为例》 | 彭文威 香港科技大学 |
| 《Stata数据清洗常用技巧》 | 彭文威 香港科技大学 |
| 《Econometric convergence test and club clustering using Stata》 | 杜克锐 山东大学 |

|
Interpreting and Visualizing Regression Models Using Stata, Second Edition 作者:
Michael N. Mitchell |

|
Data Management Using Stata: A Practical Handbook, Second Edition 作者:
Michael N. Mitchell |

|
Introduction to Time Series Using Stata, Revised Edition 作者:
Sean Becketti |

|
Generalized Linear Models and Extensions, 4th Edition 作者:
James W. Hardin和Joseph M. Hilbe |

|
A Gentle Introduction to Stata, 6th Edition 作者:
Alan C. Acock |

|
The Mata Book: A Book for Serious Programmers and Those Who Want to Be 作者:
威廉W.古尔德
|

|
Survey Weights: A Step-by-Step Guide to Calculation 作者:
Richard Valliant和Jill A. Dever
|

|
A Course in Item Response Theory and Modeling with Stata 作者:
Tenko Raykov和George A. Marcoulides
|
|
|
Interpreting and Visualizing Regression Models Using Stata, Second Edition 作者:
Michael N. Mitchell |
|
|
Data Management Using Stata: A Practical Handbook, Second Edition 作者:
Michael N. Mitchell |
|
|
Introduction to Time Series Using Stata, Revised Edition 作者:
Sean Becketti |

|
Discovering Structural Equation Modeling Using Stata, Revised Edition
Alan C. Acock |

|
An Introduction to Stata for Health Researchers, Fourth Edition Svend Juul and Morten Frydenberg |

|
A Gentle Introduction to Stata, Sixth Edition Alan C. Acock
|

|
The Workflow of Data Analysis Using Stata J. Scott Long
|

|
An Introduction to Modern Econometrics Using Stata Christopher F. Baum
|
Stata Journal为每季发行的期刊,包含了统计、资料分析、教学方法、有效地使用Stata语言及书籍回顾…等相关内容。 使用者亦可选择购买有兴趣的单篇文章。
ISI Web of Knowledge 的最新期刊引用报告,将Stata期刊列为社会科学数学方法类别期刊中的第四位,仅次于结构方程模型, 计量经济学和经济学与统计学评论。
>>教学视频
为顺应大数据时代要求,自开展Stata培训以来,我司通过活动路演、创新讲座、在线课程、线下培训等系列活动已经在全国开展了包含Stata应用方法、统计分析、文本分析、数据分析、数据清洗、Stata、cURL交互与网络爬虫、内生性问题的方法及进展、Stata编程与Mata运算、Stata编程技术与爬虫、Stata自动化报告与可重复研究、计量经济方法及Stata应用等学习活动,有近千余名师生及业界爱好者参与了学习。通过此类学习活动极大的加强了大数据分析人才的理论和实践能力。推进了大数据人才培养,以及学术成果的转化,为大数据分析领域发展做出了贡献。我司希望通过每年一届的Stata中国用户大会,深度推进国内青年学者学习热情,提升高校学术交流氛围,整合学界及业内的大量资源,进一步提高数据分析能力和科学决策的水平。
初级教程:Stata 16新功能介绍课程
主讲:StataCorp LLC |
初级教程:实证方法与Stata应用专题课程
主讲:王群勇 |
高级教程:“非线模型讲述非常故事”专题课程
主讲:王群勇 |
高级教程:“自然实验与因果推断”专题课程
主讲:王群勇 |
地址:北京市昌平区科技园区振兴路28号绿创科技大厦四层402室 网站备案号:京ICP备16049373号-1]
联系方式:+86-10-56451129



